
Demo Paper accepted at SIGIR 2018
![]() We are very pleased to announce that our group got 1 papers accepted for presentation at the demo session on SIGIR 2018: The 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, which will be held on Ann Arbor Michigan, U.S.A. July 8-12, 2018.
We are very pleased to announce that our group got 1 papers accepted for presentation at the demo session on SIGIR 2018: The 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, which will be held on Ann Arbor Michigan, U.S.A. July 8-12, 2018.
The annual SIGIR conference is the major international forum for the presentation of new research results, and the demonstration of new systems and techniques, in the broad field of information retrieval (IR). The 41st ACM SIGIR conference welcomes contributions related to any aspect of information retrieval and access, including theories and foundations, algorithms and applications, and evaluation and analysis. The conference and program chairs invite those working in areas related to IR to submit high-impact original papers for review.
Here is the accepted paper with its abstract:
- “Dynamic Composition of Question Answering Pipelines with Frankenstein” by Kuldeep Singh, Ioanna Lytra, Arun Sethupat Radhakrishna, Akhilesh Vyas and Maria Esther Vidal.
Abstract: Question answering (QA) systems provide user-friendly interfaces for retrieving answers from structured and unstructured data to natural language questions. Several QA systems, as well as related components, have been contributed by the industry and research community in recent years. However, most of these efforts have been performed independently from each other and with different focuses and their synergies in the scope of QA have not been addressed adequately.Frankenstein is a novel framework for developing QA systems over knowledge bases by integrating existing state-of-the-art QA components performing different tasks. It incorporates several reusable QA components, employs machine-learning techniques to predict best performing components and QA pipelines for a given question to generate static and dynamic executable QA pipelines. In this demo, attendees will be able to view the different functionalities of Frankenstein for performing independent QA component execution, QA component prediction given an input question as well as the static and dynamic composition of different QA pipelines.
Acknowledgment
This work has received funding from the EU H2020 R&I programme for the Marie Skłodowska-Curie action WDAqua (GA No 642795.
Looking forward to seeing you at The SIGR 2018.
Papers accepted at ICWE 2018
![]() We are very pleased to announce that our group got 2 papers accepted for presentation at the ICWE 2018 : The 18th International Conference on Web Engineering, which will be held on CÁCERES, SPAIN. 5 – 8 JUNE, 2018.
We are very pleased to announce that our group got 2 papers accepted for presentation at the ICWE 2018 : The 18th International Conference on Web Engineering, which will be held on CÁCERES, SPAIN. 5 – 8 JUNE, 2018.
The ICWE is the prime yearly international conference on the different aspects of designing, building, maintaining and using Web applications. The theme for the year 2018 — the 18th edition of the event — is Enhancing the Web with Advanced Engineering. The conference will cover the different aspects of Web Engineering, including the design, creation, maintenance, and usage of Web applications. ICWE2018 is endorsed by the International Society for the Web Engineering (ISWE) and belongs to the ICWE conference series owned by ISWE.
Here are the accepted papers with their abstracts:
- “Efficiently Pinpointing SPARQL Query Containments” by Claus Stadler, Muhammad Saleem, Axel-Cyrille Ngonga Ngomo, and Jens Lehmann.
Abstract: Query containment is a fundamental problem in database research, which is relevant for many tasks such as query optimisation, view maintenance and query rewriting. For example, recent SPARQL engines built on Big Data frameworks that precompute solutions to frequently requested query patterns, are conceptually an application of query containment. We present an approach for solving the query containment problem for SPARQL queries – the W3C standard query language for RDF datasets. Solving the query containment problem can be reduced to the problem of deciding whether a sub graph isomorphism exists between the normalized algebra expressions of two queries. Several state-of-the-art methods are limited to matching two queries only, as well as only giving a boolean answer to whether a containment relation holds. In contrast, our approach is fit for view selection use cases, and thus capable of efficiently enumerating all containment mappings among a set of queries. Furthermore, it provides the information about how two queries’ algebra expression trees correspond under containment mappings. All of our source code and experimental results are openly available.
- “OpenBudgets.eu: A Platform for SemanticallyRepresenting and Analyzing Open Fiscal Data” by Fathoni A. Musyaffa, Lavdim Halilaj, Yakun Li, Fabrizio Orlandi, Hajira Jabeen, Sören Auer, and Maria-Esther Vidal.
Abstract: Budget and spending data are among the most published Open Data datasets on the Web and continuously increasing in terms of volume over time. These datasets tend to be published in large tabular files – without predefined standards – and require complex domain and technical expertise to be used in real-world scenarios. Therefore, the potential benefits of having these datasets open and publicly available are hindered by their complexity and heterogeneity. Linked Data principles can facilitate integration, analysis and usage of these datasets. In this paper, we present OpenBudgets.eu (OBEU), a Linked Data-based platform supporting the entire open data life-cycle of budget and spending datasets: from data creation to publishing and exploration. The platform is based on a set of requirements specifically collected by experts in the budget and spending data domain. It follows a micro-services architecture that easily integrates many different software modules and tools for analysis, visualization and transformation of data. Data i represented according to a logical model for open fiscal data which is translated into both RDF data and a tabular data formats. We demonstrate the validity of the implemented OBEU platform with real application scenarios and report on a user study conducted to confirm its usability.
Acknowledgment
This work was partly supported by the grant from the European Unions Horizon 2020 research Europe flag and innovation programme for the projects HOBBIT (GA no. 688227), QROWD (GA no. 732194), WDAqua (GA no. 642795), OpenBudgets.eu the EU H2020 (GA no. 645833) and DAAD scholarship.
Looking forward to seeing you at ICWE 2018.
Invited talk by Dr. Anastasia Dimou
 On Wednesday, 21st of March Anastasia Dimou from the Internet Technology & Data Science Lab visited SDA and gave a talk entitled “High Quality Linked Data Generation from Heterogeneous data”
On Wednesday, 21st of March Anastasia Dimou from the Internet Technology & Data Science Lab visited SDA and gave a talk entitled “High Quality Linked Data Generation from Heterogeneous data”
Anastasia Dimou is a Post-Doc Researcher at the Internet Technology & Data Science Lab at Gent University, Belgium. Anastasia joined the IDLab research group in February 2013. Her research expertise lies in the area of the Semantic Web, Linked Data Generation and Publication, Data Quality and Integration, Knowledge Representation and Management. She has broad experience on Semantic Wikis and Classification. As part of her research, she investigated a uniform language for describing the mapping rules for generating high-quality Linked Data from multiple heterogeneous data formats and access interfaces and she also conducted research on Linked Data generation and publishing workflows. Her research activities led to the development of the RML tool chain (RMLProcessor, RMLEditor, RMLValidator, and RMLWorkbench). Anastasia has been involved in different national and l research projects and publications.
Prof. Jens Lehmann invited the speaker to the bi-weekly “SDA colloquium presentations”. The goal of her visit was to exchange experience and ideas on RML tools specialized for data quality and on the fly mapping, including heterogeneous dataset mapping into LOD. Apart from presenting various use cases where RML tools were used, she introduced a declarative RML serialization which models the mapping rules using the well-known yaml language. Anastasia shared with our group future research problems and challenges related to this research area.
In her talk, she introduced a full workflow aka the RML tool chain which models components of an RML mapping lifecycle. She discussed its application to the structure of heterogeneous data sources. Anastasia Dimou mentioned that adding support for data quality during the mapping shall allow users to efficiently explore a structured search space to enable the future violations not only map the range of the known domain but also help to discover new knowledge from the existing knowledge base worth mapping.
During the visit, SDA core research topics and main research projects were presented in a (successful!) attempt to find an intersection on the future collaborations with Anastasia and her research group.
As an outcome of this visit, we expect to strengthen our research collaboration networks with the Internet Technology & Data Science Lab at UGent, mainly on combining semantic knowledge for exploratory and mapping tools and apply those techniques for a very large-scale KG using our distributed analytics framework SANSA and DBpedia.
Papers and a tutorial accepted at ESWC 2018

We are very pleased to announce that our group got 3 papers accepted for presentation at the ESWC 2018 : The 15th edition of The Extended Semantic Web Conference, which will be held on June 3-7, 2018 in Heraklion, Crete, Greece.
The ESWC is a major venue for discussing the latest scientific results and technology innovations around semantic technologies. Building on its past success, ESWC is seeking to broaden its focus to span other relevant related research areas in which Web semantics plays an important role. ESWC 2018 will present the latest results in research, technologies, and applications in its field. Besides the technical program organized over twelve tracks, the conference will feature a workshop and tutorial program, a dedicated track on Semantic Web challenges, system descriptions and demos, a posters exhibition and a doctoral symposium.
Here are the accepted papers with their abstracts:
- “Formal Query Generation for Question Answering over Knowledge Bases” by Hamid Zafar, Giulio Napolitano and Jens Lehmann.
Abstract: Question answering (QA) systems often consist of several components such as Named Entity Disambiguation (NED), Relation Extraction (RE), and Query Generation (QG). In this paper, we focus on the QG process of a QA pipeline on a large-scale Knowledge Base (KB), with noisy annotations and complex sentence structures. We therefore propose SQG, a SPARQL Query Generator with modular architecture, enabling easy integration with other components for the construction of a fully functional QA pipeline. SQG can be used on large open-domain KBs and handle noisy inputs by discovering a minimal subgraph based on uncertain inputs, that it receives from the NED and RE components. This ability allows SQG to consider a set of candidate entities/relations, as opposed to the most probable ones, which leads to a significant boost in the performance of the QG component. The captured subgraph covers multiple candidate walks, which correspond to SPARQL queries. To enhance the accuracy, we present a ranking model based on Tree-LSTM that takes into account the syntactical structure of the question and the tree representation of the candidate queries to find the one representing the correct intention behind the question.
- “Frankenstein: a Platform Enabling Reuse of Question Answering Components Paper” Resource Track by Kuldeep Singh, Andreas Both, Arun Sethupat, Saeedeh Shekarpour.
Abstract: Recently remarkable trials of the question answering (QA) community yielded in developing core components accomplishing QA tasks. However, implementing a QA system still was costly. While aiming at providing an efficient way for the collaborative development of QA systems, the Frankenstein framework was developed that allows dynamic composition of question answering pipelines based on the input question. In this paper, we are providing a full range of reusable components as independent modules of Frankenstein populating the ecosystem leading to the option of creating many different components and QA systems. Just by using the components described here, 380 different QA systems can be created offering the QA community many new insights. Additionally, we are providing resources which support the performance analyses of QA tasks, QA components and complete QA systems. Hence, Frankenstein is dedicated to improve the efficiency within the research process w.r.t. QA.
- “Using Ontology-based Data Summarization to Develop Semantics-aware Recommender Systems” by Tommaso Di Noia, Corrado Magarelli, Andrea Maurino, Matteo Palmonari, Anisa Rula.
Abstract: In the current information-centric era, recommender systems are gaining momentum as tools able to assist users in daily decision-making tasks. They may exploit users’ past behavior combined with side/contextual information to suggest them new items or pieces of knowledge they might be interested in. Within the recommendation process, Linked Data (LD) have been already proposed as a valuable source of information to enhance the predictive power of recommender systems not only in terms of accuracy but also of diversity and novelty of results. In this direction, one of the main open issues in using LD to feed a recommendation engine is related to feature selection: how to select only the most relevant subset of the original LD dataset thus avoiding both useless processing of data and the so called “course of dimensionality” problem. In this paper we show how ontology-based (linked) data summarization can drive the selection of properties/features useful to a recommender system. In particular, we compare a fully automated feature selection method based on ontology-based data summaries with more classical ones and we evaluate the performance of these methods in terms of accuracy and aggregate diversity of a recommender system exploiting the top-k selected features. We set up an experimental testbed relying on datasets related to different knowledge domains. Results show the feasibility of a feature selection process driven by ontology-based data summaries for LD-enabled recommender systems.
Acknowledgement
These work were supported by an EU H2020 grant provided for the HOBBIT project (GA no. 688227), by German Federal Ministry of Education and Research (BMBF) funding for the project SOLIDE (no. 13N14456) as well as by European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 642795, WDAqua project.
Furthermore, we are pleased to inform that we got a tutorial accepted, which will be co-located with the ESWC 2018.
Here is the accepted tutorial and its short description:
- How to build a Question Answering system overnight
Author: Andreas Both, Denis Lukovnikov, Gaurav Maheshwari, Ioanna Lytra, Jens Lehmann, Kuldeep Singh, Mohnish Dubey, Priyansh Trivedi
Аbstract: With this tutorial, we aim to provide the participants with an overview of the field of Question Answering, insights into commonly faced problems, its recent trends, and developments. At the end of the tutorial, the audience would have hands-on experience of developing two working QA systems- one based on rule-based semantic parsing, and another, a deep learning based method. In doing so, we hope to provide a suitable entry point for the people new to this field and ease their process of making informed decisions while creating their own QA systems.
Website: http://qatutorial.sda.tech/
Looking forward to seeing you at The ESWC 2018.
Paper accepted at Semantic Web Journal
![]()
We are very pleased to announce that our group got a paper accepted at Semantic Web Journal on the Benchmarking Linked Data 2017 issue.
The journal Semantic Web – Interoperability, Usability, Applicability (published and printed by IOS Press, ISSN: 1570-0844), in short Semantic Web journal, brings together researchers from various fields which share the vision and need for more effective and meaningful ways to share information across agents and services on the future internet and elsewhere. As such, Semantic Web technologies shall support the seamless integration of data, on-the-fly composition, and interoperation of Web services, as well as more intuitive search engines. The semantics – or meaning – of information, however, cannot be defined without a context, which makes personalization, trust, and provenance core topics for Semantic Web research. New retrieval paradigms, user interfaces, and visualization techniques have to unleash the power of the Semantic Web and at the same time hide its complexity from the user. Based on this vision, the journal welcomes contributions ranging from theoretical and foundational research over methods and tools to descriptions of concrete ontologies and applications in all areas.
Here is the accepted paper with its abstract:
- “SML-Bench — A Benchmarking Framework for Structured Machine Learning” by Patrick Westphal, Lorenz Bühmann, Simon Bin, Hajira Jabeen, Jens Lehmann.
Abstract: The availability of structured data has increased significantly over the past decade and several approaches to learn from structured data have been proposed. These logic-based, inductive learning methods are often conceptually similar, which would allow a comparison among them even if they stem from different research communities. However, so far no efforts were made to define an environment for running learning tasks on a variety of tools, covering multiple knowledge representation languages. With SML-Bench, we propose a benchmarking framework to run inductive learning tools from the ILP and semantic web communities on a selection of learning problems. In this paper, we present the foundations of SML-Bench, discuss the systematic selection of benchmarking datasets and learning problems, and showcase an actual benchmark run on the currently supported tools.
Acknowledgement
This part of work is supported were supported by grants from the EU FP7 Programme for the project GeoKnow (GA no. 318159) as well as for the German Research Foundation project GOLD and the German Ministry for Economic Affairs and Energy project SAKE (GA no. 01MD15006E), the European Union’s Horizon 2020 research and innovation programme for the project SLIPO (GA no. 731581) as well as the European Union’s H2020 research and innovation action HOBBIT (GA 688227) and the CSA BigDataEurope (GA No 644564).
SANSA Collaboration with Alethio
The SANSA team is excited to announce our collaboration with Alethio (a ConsenSys formation). SANSA is the major distributed, open source solution for RDF querying, reasoning and machine learning. Alethio is building an Ethereum analytics platform that strives to provide transparency over what’s happening on the Ethereum p2p network, the transaction pool and the blockchain and provide “blockchain archeology”. Their 5 billion triple data set contains large scale blockchain transaction data modelled as RDF according to the structure of the Ethereum ontology. EthOn – The Ethereum Ontology – is a formalization of concepts/entities and relations of the Ethereum ecosystem represented in RDF and OWL format. It describes all Ethereum terms including blocks, transactions, contracts, nonces etc. as well as their relationships. Its main goal is to serve as a data model and learning resource for understanding Ethereum.
Alethio is interested in using SANSA as a scalable processing engine for their large-scale batch and stream processing tasks, such as querying the data in real time via SPARQL and performing related analytics on a wide range of subjects (e.g. asset turnover for sets of accounts, attack pattern detection or Opcode usage statistics). At the same time, SANSA is interested in further industrial pilot applications for testing the scalability on larger datasets, mature its code base and gain experience on running the stack on production clusters. Specifically, the initial goal of Alethio was to load a 2TB EthOn dataset containing more than 5 billion triples and then performing several analytic queries on it with up to three inner joins. The queries are used to characterize movement between groups of ethereum accounts (e.g. exchanges or investors in ICOs) and aggregate their in and out value flow over the history of the Ethereum blockchain. The experiments were successfully run by Alethio on a cluster with up to 100 worker nodes and 400 cores that have a total of over 3TB of memory available.
“I am excited to see that SANSA works and scales well to our data. Now, we want to experiment with more complex queries and tune the Spark parameters to gain the optimal performance for our dataset” said Johannes Pfeffer, co-founder of Alethio. “I am glad that Alethio managed to run their workload and to see how well our methods scale to a 5 billion triple dataset”, added Gezim Sejdiu, PhD student at the Smart Data Analytics Group and SANSA core developer.
Parts of the SANSA team, including its leader Prof. Jens Lehmann as well as Dr. Hajira Jabeen, Dr. Damien Graux and Gezim Sejdiu, will now continue the collaboration together with the data science team of Alethio after those successful experiments. Beyond the above initial tests, we are jointly discussing possibilities for efficient stream processing in SANSA, further tuning of aggregate queries as well as suitable Apache Spark parameters for efficient processing of the data. In the future, we want to join hands to optimize the performance of loading the data (e.g. reducing the disk footprint of datasets using compression techniques allowing then more efficient SPARQL evaluation), handling the streaming data, querying, and analytics in real time.
The SANSA team is happily looking forward to further interesting scientific research as well as industrial adaptation.
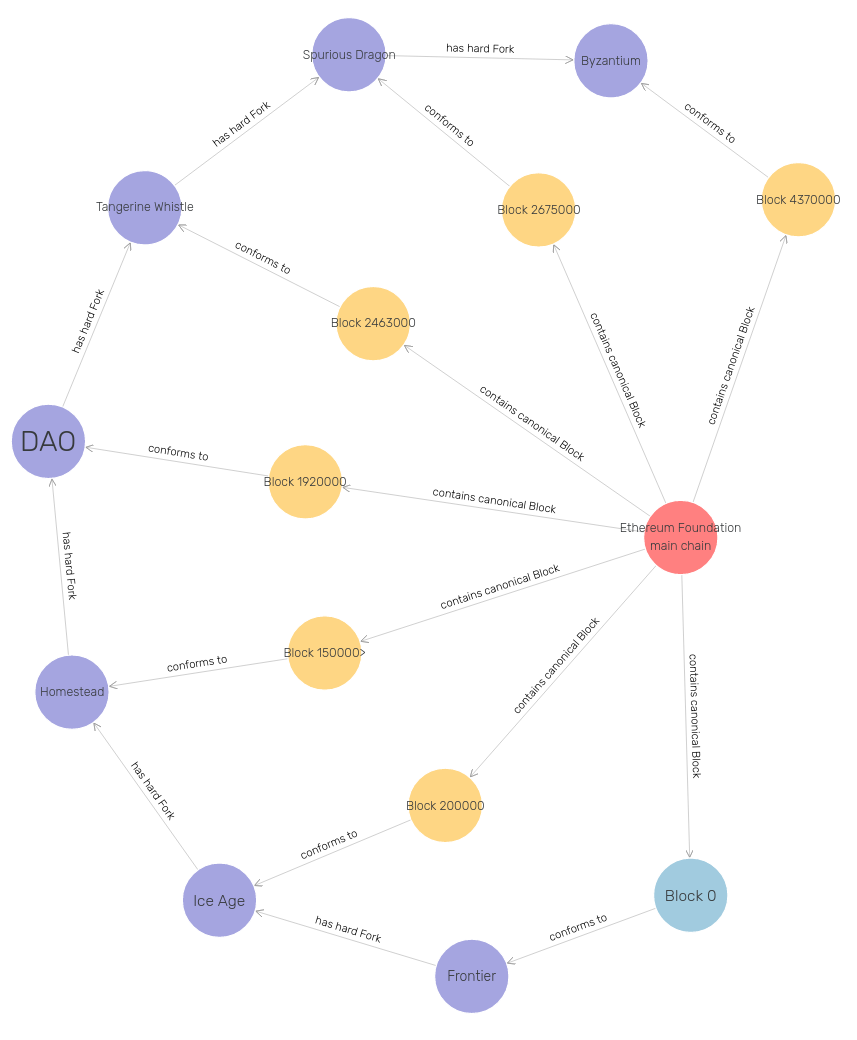

Core model of the fork history of the Ethereum Blockchain modeled in EthOn
Paper accepted at ICLR 2018

We are very pleased to announce that our group in collaboration with Fraunhofer IAIS got a paper accepted for poster presentation at ICLR 2018 : The Sixth International Conference on Learning Representations, which will be held on April 30 – May 03, 2018 in Vancouver Convention Center, Vancouver CANADA.
The Sixth edition of ICLR will offer many opportunities to present and discuss latest advances in the performance of machine learning methods and deep learning. With a broad view of the field and include topics such as feature learning, metric learning, compositional modeling, structured prediction, reinforcement learning, and issues regarding large-scale learning and non-convex optimization. The range of domains to which these techniques apply is also very broad, from vision to speech recognition, text understanding, gaming, music, etc.
Here is the accepted paper with its abstract:
- “On the regularization of Wasserstein GANs” by Henning Petzka, Asja Fischer, Denis Lukovnikov
Abstract: Since their invention, generative adversarial networks (GANs) have become a popular approach for learning to model a distribution of real (unlabeled) data. Convergence problems during training are overcome by Wasserstein GANs which minimize the distance between the model and the empirical distribution in terms of a different metric, but thereby introduce a Lipschitz constraint into the optimization problem. A simple way to enforce the Lipschitz constraint on the class of functions, which can be modeled by the neural network, is weight clipping. Augmenting the loss by a regularization term that penalizes the deviation of the gradient norm of the critic (as a function of the network’s input) from one, was proposed as an alternative that improves training. We present theoretical arguments why using a weaker regularization term enforcing the Lipschitz constraint is preferable. These arguments are supported by experimental results on several data sets.
Acknowledgments
This part of work is supported by WDAqua : Marie Skłodowska-Curie Innovative Training Network (GA no. 642795).
Looking forward to seeing you at ICLR 2018.
Invited talk by Svitlana Vakulenko
 On Wednesday, 31st of January Svitlana Vakulenko from the Institute for Information Business visited SDA and gave a talk entitled “Semantic Coherence for Conversational Browsing of a Knowledge Graph”
On Wednesday, 31st of January Svitlana Vakulenko from the Institute for Information Business visited SDA and gave a talk entitled “Semantic Coherence for Conversational Browsing of a Knowledge Graph”
Svitlana Vakulenko is a researcher at the Institute for Information Business at WU Wien and a PhD student in the Computer Science Department at TU Wien. Her research expertise lies in the area of machine learning for natural language processing. She has been involved in several international research projects and is currently working in CommuniData FFG project (communidata.at), which aims to enhance the usability of Open Data and its accessibility for non-expert users in local communities. She is involved in other projects as well with the main focus on Question Answering from Tabular data and Open Data Conversational Search and Exploratory Search.
Prof. Jens Lehmann invited the speaker to the bi-weekly “SDA colloquium presentations”. The goal of her visit was to exchange experience and ideas on semantic search and dialogue systems techniques specialized for question answering, including conversational search and exploratory search. Apart from presenting various use cases where semantic exploration using table data and open data has been used she introduced a framework which models these conversational browsing systems. Svitlana shared with our group future research problems and challenges related to this research area and shown that the Semantic Coherence will provide more insight and meaningful results to the conversational browsing scenario.
In this talk, she introduces the task of conversational browsing that goes beyond Question Answering. A framework which models components of a conversational browsing system has been presented and discussed its application to the structure of a Knowledge Graph (KG). She mentioned that adding support for conversational browsing functionality shall allow users to efficiently explore a structured search space to enable the future conversational search systems not only answer a range of questions but also help to discover questions worth asking.
During the visit, SDA core research topics and main research projects were presented in an attempt to find an intersection on the future collaborations with Svitlana and her research group.
As an outcome of this visit, we expect to strengthen our research collaboration networks with the Institute of Information Business at WU Wien, mainly on combining semantic knowledge for exploratory and conversation search and apply those techniques for a very large-scale KG using our distributed analytics framework SANSA.
Papers and workshops accepted at TheWebConference (ex WWW) 2018
 We are very pleased to announce that our group got 2 papers accepted for presentation at the The 2018 edition of The Web Conference (27th edition of the former WWW conference), which will be held on April 23-27, 2018 in Lyon, France.
We are very pleased to announce that our group got 2 papers accepted for presentation at the The 2018 edition of The Web Conference (27th edition of the former WWW conference), which will be held on April 23-27, 2018 in Lyon, France.
The 2018 edition of The Web Conference will offer many opportunities to present and discuss latest advances in academia and industry. This first joint call for contributions provides a list of the first calls for: research tracks, workshops, tutorials, exhibition, posters, demos, developers’ track, W3C track, industry track, PhD symposium, challenges, minute of madness, international project track, W4A, hackathon, the BIG web, journal track.
Here are the accepted papers with their abstracts:
- “DL-Learner – A Framework for Inductive Learning on the Semantic Web” by Lorenz Bühmann, Patrick Westphal, Jens Lehmann and Simon Bin (Journal paper track).
Abstract: In this system paper, we describe the DL-Learner framework, which supports supervised machine learning using OWL and RDF for background knowledge representation. It can be beneficial in various data and schema analysis tasks with applications in different standard machine learning scenarios, e.g. in the life sciences, as well as Semantic Web specific applications such as ontology learning and enrichment. Since its creation in 2007, it has become the main OWL and RDF-based software framework for supervised structured machine learning and includes several algorithm implementations, usage examples and has applications building on top of the framework. The article gives an overview of the framework with a focus on algorithms and use cases.
- “Why Reinvent the Wheel- Let’s Build Question Answering Systems Together” by Kuldeep Singh, Arun Sethupat Radhakrishna, Andreas Both, Saeedeh Shekarpour, Ioanna Lytra, Ricardo Usbeck, Akhilesh Vyas, Akmal Khikmatullaev, Dharmen Punjani, Christoph Lange, Maria-Esther Vidal, Jens Lehmann and Sören Auer ( Research track).
Abstract: Modern question answering (QA) systems need to flexibly integrate a number of components specialised to fulfil specific tasks in a QA pipeline. Key QA tasks include Named Entity Recognition and Disambiguation, Relation Extraction, and Query Building. Since a number of different software components exist, implementing different strategies for each of these tasks, a major challenge when building QA systems, is how to select and combine the most suitable components into a QA system, given the characteristics of a question. We study this optimisation problem and train Classifiers, which take features of a question as input and have the goal of optimising the selection of QA components based on those features. We then devise a greedy algorithm to identify the pipelines that include the suitable components and can effectively answer the given question. We implement this model within Frankenstein, a QA framework able to select QA components and compose QA pipelines. We evaluate the effectiveness of the pipelines generated by Frankenstein using the QALD and LC-QuAD benchmarks. These results not only suggest that Frankenstein precisely solves the QA optimisation problem, but also enables the automatic composition of optimised QA pipelines, which outperform the static Baseline QA pipeline. Thanks to this flexible and fully automated pipeline generation process, new QA components can be easily included in Frankenstein, thus improving the performance of the generated pipelines.
Acknowledgement
These work were supported by grants from the EU FP7 Programme for the project GeoKnow (GA no. 318159) as well as for the German Research Foundation project GOLD and the German Ministry for Economic Affairs and Energy project SAKE (GA no. 01MD15006E), the European Union’s Horizon 2020 research and innovation programme for the project SLIPO (GA no. 731581), the EU Horizon 2020 R&I programme for the Marie Sklodowska Curie action WDAqua (GA No 642795), Eurostars project QAMEL (E!9725) as well as the European Union’s H2020 research and innovation action HOBBIT (GA 688227) and the CSA BigDataEurope (GA No 644564).
Furthermore, we are pleased to inform that we got the following workshops, which will be co-located with The Web Conference 2018.
Here is the accepted workshops and their short description:
- Linked Data on the Web (LDOW2018) by Tim Berners-Lee (W3C/MIT, USA), Sarven Capadisli (University of Bonn, Germany), Stefan Dietze (Leibniz Universität Hannover,Germany), Aidan Hogan (Universidad de Chile, Chile), Krzysztof Janowicz (University of California, Santa Barbara, US) and Jens Lehmann (University of Bonn, Germany)
The Web is developing from a medium for publishing textual documents into a medium for sharing structured data. This trend is fueled on the one hand by the adoption of the Linked Data principles by a growing number of data providers. On the other hand, large numbers of websites have started to semantically mark up the content of their HTML pages and thus also contribute to the wealth of structured data available on the Web. The 11th Workshop on Linked Data on the Web (LDOW2018) aims to stimulate discussion and further research into the challenges of publishing, consuming, and integrating structured data from the Web as well as mining knowledge from the global Web of Data.
Topics of interest for the workshop include, but are not limited to, the following:- Web Data Quality Assessment
- Web Data Cleansing
- Integrating Web Data from Large Numbers of Data Sources
- Mining the Web of Data
- Linked Data Applications
Social media hashtag: #LDOW2018
- Semantics, Analytics, Visualisation: Enhancing Scholarly Dissemination by Alejandra Gonzalez-Beltran (Oxford e-Research Centre, University of Oxford, Oxford, UK), Francesco Osborne (Knowledge Media Institute, Open University, Milton Keynes, UK), Silvio Peroni (Department of Computer Science and Engineering, University of Bologna, Bologna, Italy), Sahar Vahdati (Smart Data Analytics, University of Bonn, Bonn, Germany)
After the great success of the past three editions, we are pleased to announce SAVE-SD 2018, which wants to bring together publishers, companies and researchers from different fields (including Document and Knowledge Engineering, Semantic Web, Natural Language Processing, Scholarly Communication, Bibliometrics, Human-Computer Interaction, Information Visualisation, Bioinformatics, and Life Sciences) in order to bridge the gap between the theoretical/academic and practical/industrial aspects in regards to scholarly data.
The following topics will be addressed:- semantics of scholarly data, i.e. how to semantically represent, categorise, connect and integrate scholarly data, in order to foster reusability and knowledge sharing;
- analytics on scholarly data, i.e. designing and implementing novel and scalable algorithms for knowledge extraction with the aim of understanding research dynamics, forecasting research trends, fostering connections between groups of researchers, informing research policies, analysing and interlinking experiments and deriving new knowledge;
- visualisation of and interaction with scholarly data, i.e. providing novel user interfaces and applications for navigating and making sense of scholarly data and highlighting their patterns and peculiarities.
Looking forward to seeing you at The Web Conference (ex WWW) 2018
Christmas Time at SDA – Time to look back at 2017
 We are looking back at a busy and successful year 2017 full of new members, inspirational discussions, exciting conferences, a lot of accepted papers and awards as well as new software releases.
We are looking back at a busy and successful year 2017 full of new members, inspirational discussions, exciting conferences, a lot of accepted papers and awards as well as new software releases.
Below is a short summary of the main cornerstones for 2017:
The growth of the group in 2017
SDA is a new group, but not new in the field :). As a group, it was founded by Prof. Dr. Jens Lehmann at the beginning of 2016. The group has members at the University of Bonn with associated researchers at the Fraunhofer Institute for Intelligent Analysis and Information Systems (IAIS) and the Institute for Applied Computer Science Leipzig. Within 2017, the group has grown from 20 members to around 55 members (1 Professor, 1 Akademischer Rat / Assistant Professor, 11 PostDocs, 31 PhD Students,11 master students) as you can see on our team page.
An interesting future for AI and knowledge graphs
Artificial intelligence / machine learning and semantic technologies / knowledge graphs are central topics for SDA. Throughout the year, we have been able to achieve a range of interesting research achievements. This ranges from internationally leading results in question answering over knowledge graphs, to scalable distributed querying, inference and analysis of large RDF datasets as well as new perspectives on industrial data spaces and data integration. Among the race for ever improving achievements in AI, which go far beyond what many could have imagined 10 years ago, our researchers were able to deliver important contributions and continue to shape different sub areas of the growing AI research landscape.
Papers accepted
We had 46 papers accepted at well-known conferences (i.e The Web Conference 2018, WWW 2017, AAAI 2017, ISWC 2017, ESWC 2017, DEXA 2017, SEMANTiCS 2017, K-CAP 2017, WI 2017, KESW 2017, IEEE BigData 2017, NIPS 2017, TPDL 2017, ICSC 2018, ICEGOV 2018 and more. We estimate our articles to be cited around 3000+ times per year (based on Google Scholar profiles).
Awards
We received several awards in 2017 – click on the posts to find out more:

- A Ten-Year Best Paper, a Demo Award and a Best Reviewer Award at ISWC 2017
- A Seven-Year Best Paper Award at ESWC 2017
- A Honorary Mention Award at TPDL 2017
- A Best Paper Award at SEMANTiCS 2017
- A Best Paper Award at DEXA 2017
- A Best Paper Award at the Pattern Recognition Journal
- The best PhD thesis in Computer Science in 2016 from the Brazilian Government Council
- NVIDIA Pioneering Research Award at ICML 2017
- Paper of the month at Fraunhofer IAIS (November 2017, March 2017)
Software releases
SANSA – An open source data flow processing engine for performing distributed computation over large-scale RDF datasets had 2 successfully released during 2017 (SANSA 0.3 and SANSA 0.2).
From the funded projects we were happy to launch the final release of the Big Data Europe platform – an open source Big Data Processing Platform allowing users to install numerous big data processing tools and frameworks and create working data flow applications.
There were several other releases:
- SML-Bench – A Structured Machine Learning benchmark framework 0.2 has been released.
- WebVOWL – A Web-based Visualization of Ontologies had several releases in 2017.
- OpenResearch.org – A Crowd-Sourcing platform for collaborative management of scholarly metadata reached coverage of more than 5K computer science conferences in 2017.
Furthermore, SDA deeply values team bonding activities. 🙂 Often we try to introduce fun activities that involve teamwork and teambuilding. At our X-mas party, we enjoyed a very international and lovely dinner together, we played a `Secret Santa` and Pantomime game.

Long-term team building through deeper discussions, genuine connections and healthy communication helps us to connect within the group!
Many thanks to all of you who have accompanied and supported us on this way!
Jens Lehmann on behalf of The SDA Research Team