
Workshop Papers accepted at ICML/FAIM 2018
 We are very pleased to announce that our group got 2 workshop papers accepted for presentation at The Federated Artificial Intelligence Meeting (FAIM) → NAMPI workshop co-organized with ICML, IJCAI/ECAI, AAMAS. The workshop took place in Stockholm, Sweden on the 15th of July 2018.
We are very pleased to announce that our group got 2 workshop papers accepted for presentation at The Federated Artificial Intelligence Meeting (FAIM) → NAMPI workshop co-organized with ICML, IJCAI/ECAI, AAMAS. The workshop took place in Stockholm, Sweden on the 15th of July 2018.
The aim of the NAMPI workshop was to bring researchers and practitioners from both academia and industry, in the areas of deep learning, program synthesis, probabilistic programming, programming languages, inductive programming and reinforcement learning, together to exchange ideas on the future of program induction with a special focus on neural network models and abstract machines. Through this workshop we look to identify common challenges, exchange ideas among and lessons learned from the different fields, as well as establish a (set of) standard evaluation benchmark(s) for approaches that learn with abstraction and/or reason with induced programs.
Here are the accepted papers with their abstracts:
- Neural Machine Translation for Query Construction and Composition by Tommaso Soru, Edgard Marx, André Valdestilhas, Diego Esteves, Diego Moussallem and Gustavo Publio.
Abstract: Research on question answering with knowledge base has recently seen an increasing use of deep architectures. In this extended abstract, we study the application of the neural machine translation paradigm for question parsing. We employ a sequence-to-sequence model to learn graph patterns in the SPARQL graph query language and their compositions. Instead of inducing the programs through question-answer pairs, we expect a semi-supervised approach, where alignments between questions and queries are built through templates. We argue that the coverage of language utterances can be expanded using late notable works in natural language generation.
- ML-Schema: Exposing the Semantics of Machine Learning with Schemas and Ontologies by Gustavo Correa Publio, Diego Esteves, Agnieszka Ławrynowicz, Panče Panov, Larisa Soldatova, Tommaso Soru, Joaquin Vanschoren and Hamid Zafar.
Abstract: The ML-Schema, proposed by the W3C Machine Learning Schema Community Group, is a top-level ontology that provides a set of classes, properties, and restrictions for representing and interchanging information on machine learning algorithms, datasets, and experiments. It can be easily extended and specialized and it is also mapped to other more domain-specific ontologies developed in the area of machine learning and data mining. In this paper we overview existing state-of-the-art machine learning interchange formats and present the first release of ML-Schema, a canonical format resulted of more than seven years of experience among different research institutions. We argue that exposing semantics of machine learning algorithms, models, and experiments through a canonical format may pave the way to better interpretability and to realistically achieve the full interoperability of experiments regardless of platform or adopted workflow solution.
Acknowledgment
This work was partially supported by NEAR AI.
Demo and Poster Papers accepted at ISWC 2018
 We are very pleased to announce that our group got 4 demo/poster papers accepted for presentation at ISWC 2018 : The 17th International Semantic Web Conference, which will be held on October 8 – 12, 2018 in Monterey, California, USA.
We are very pleased to announce that our group got 4 demo/poster papers accepted for presentation at ISWC 2018 : The 17th International Semantic Web Conference, which will be held on October 8 – 12, 2018 in Monterey, California, USA.
The International Semantic Web Conference (ISWC) is the premier international forum where Semantic Web / Linked Data researchers, practitioners, and industry specialists come together to discuss, advance, and shape the future of semantic technologies on the web, within enterprises and in the context of the public institution.
Here is the list of the accepted papers with their abstract:
- “STATisfy Me: What are my Stats?” by Gezim Sejdiu, Ivan Ermilov, Mohamed Nadjib Mami and Jens Lehmann
Abstract: The increasing adoption of the Linked Data format, RDF, over the last two decades has brought new opportunities.
It has also raised new challenges though, especially when it comes to managing and processing large amounts of RDF data. In particular, assessing the internal structure of a data set is important, since it enables users to understand the data better. One prominent way of assessment is computing statistics about the instances and schema of a data set. However, computing statistics of large RDF data is computationally expensive.
To overcome this challenging situation, we previously built DistLODStats, a framework for parallel calculation of 32 statistical criteria over large RDF datasets, based on Apache Spark. Running DistLODStats is, thus, done via submitting jobs to a Spark cluster. Often times, this process is done manually, either by connecting to the cluster machine or via a dedicated resource manager. This approach is inconvenient as it requires acquiring new software skills as well as the direct interaction of users with the cluster.
In order to make the use of DistLODStats easier, we propose in this paper an approach for triggering RDF statistics calculation remotely simply using HTTP requests. DistLODStats is built as a plugin into the larger SANSA Framework and makes use of Apache Livy, a novel lightweight solution for interacting with Spark cluster via a REST Interface.
- “Joint Entity and Relation Linking using EARL” by Debayan Banerjee, Mohnish Dubey, Debanjan Chaudhuri and Jens Lehmann
Abstract: In order to answer natural language questions over knowledge graphs,most processing pipelines involve entity and relation linking. Traditionally, entity linking and relation linking have been performed either as dependent sequential tasks or independent parallel tasks. In this demo paper, we present EARL, which performs entity linking and relation linking as a joint single task. The system determines the best semantic connection between all keywords of the question by referring to the knowledge graph. This is achieved by exploiting the connection density between entity candidates and relation candidates. EARL uses bloom filters for faster retrieval of connection density and uses an extended label vocabulary for higher recall to improve the overall accuracy
- “Generating SPARQL Query Containment Benchmarks using the SQCFramework” by Muhammad Saleem , Qaiser Mehmood, Claus Stadler, Jens Lehmann and Axel-Cyrille Ngonga Ngomo
Abstract: In this demo paper, we present the interface of the SQCFramework, a SPARQL query containment benchmark generation framework. SQCFramework is able to generate customized SPARQL containment benchmarks from real SPARQL query logs. To this end, the framework makes use of different clustering techniques. It is flexible enough to generate benchmarks of varying sizes and complexities according to user-defined criteria on important SPARQL features for query containment benchmarking. We evaluate the usability of the interface by using the standard system usability scale questionnaire. Our overall usability score of 82.33 suggests that the online interface is consistent, easy to use, and the various functions of the system are well integrated.
- “Synthesizing a Knowledge Graph of Data Scientist Job Offers with MINTE+” by Mikhail Galkin, Diego Collarana, Mayesha Tasnim and Maria-Esther Vidal
Abstract: Data Scientist is one of the most sought-after jobs of this decade. In order to analyze the job market in this domain, interested institutions have to integrate numerous job advertising coming from heterogeneous Web sources e.g., job portals, company websites, professional community platforms such as StackOverflow, GitHub, etc. In this demo, we show the application of the RDF Molecule-Based Integration Framework MINTE+ in the domain-specific application of job market analysis. The use of RDF molecules for knowledge representation is a core element of the framework gives MINTE+ enough flexibility to integrate job advertising from different web resources and countries. Attendees will observe how exploration and analysis of the data science job market in Europe can be facilitated by synthesizing at query time a consolidated knowledge graph of job advertising. The demo is available at: https://github.com/RDF-Molecules/MINTE/blob/master/README.md#live-demo
Acknowledgment
This work has received funding from the EU Horizon 2020 projects BigDataEurope (GA 644564) and QROWD (GA no. 723088), the Marie Skłodowska-Curie action WDAqua(GA No 642795), and HOBBIT (GA. 688227), and (project SlideWiki, grant no. 688095), and the German Ministry of Education and Research (BMBF) in the context of the projects LiDaKrA (Linked-Data-basierte Kriminalanalyse, grant no. 13N13627) and InDaSpacePlus (grant no. 01IS17031).
Looking forward to seeing you at The ISWC 2018.
Paper and Poster Papers accepted at SEMANTICS 2018
![]() We are very pleased to announce that our group got two papers and two poster papers accepted for presentation at SEMANTiCS 2018 conference which will take place in Vienna, Austria on 10th – 13th of September 2018.
We are very pleased to announce that our group got two papers and two poster papers accepted for presentation at SEMANTiCS 2018 conference which will take place in Vienna, Austria on 10th – 13th of September 2018.
SEMANTiCS is an established knowledge hub where technology professionals, industry experts, researchers and decision makers can learn about new technologies, innovations and enterprise implementations in the fields of Linked Data and Semantic AI. Since 2005, the conference series has focused on semantic technologies, which are today together with other methodologies such as NLP and machine learning the core of intelligent systems. The conference highlights the benefits of standards-based approaches.
Here is the list of accepted papers with their abstracts:
- “Profiting from Kitties on Ethereum: Leveraging Blockchain RDF with SANSA” by Damien Graux, Gezim Sejdiu, Hajira Jabeen, Jens Lehmann, Danning Sui, Dominik Muhs and Johannes Pfeffer (Poster & Demo Track)
Abstract: In this poster, we will present attendees how the recent state-of-the-art Semantic Web tool SANSA could be used to tackle blockchain specific challenges. In particular, the poster will focus on the use case of CryptoKitties: a popular Ethereum-based online game where users are able to trade virtual kitty pets in a secure way.
- “SPIRIT: A Semantic Transparency and Compliance Stack” by Patrick Westphal, Javier Fernández, Sabrina Kirrane and Jens Lehmann (Poster & Demo Track)
Abstract: The European General Data Protection Regulation (GDPR) sets new precedents for the processing of personal data. In this paper, we propose an architecture that provides an automated means to enable transparency with respect to personal data processing and sharing transactions and compliance checking with respect to data subject usage policies and GDPR legislative obligations.
- “SemSur: A Core Ontology for the Semantic Representation of Research Findings” by Said Fathalla, Sahar Vahdati, Sören Auer and Christoph Lange (Research & Innovation)
Abstract: The way how research is communicated using text publications has not changed much over the past decades. We have the vision that ultimately researchers will work on a common structured knowledge base comprising comprehensive semantic and machine-comprehensible descriptions of their research, thus making research contributions more transparent and comparable. We present the SemSur ontology for semantically capturing the information commonly found in survey and review articles. SemSur is able to represent scientific results and to publish them in a comprehensive knowledge graph, which provides an efficient overview of a research field, and to compare research findings withrelated works in a structured way, saving researchers a significant amount of time and effort. The new release of SemSur covers more domains, defines better alignment with external ontologies and rules for eliciting implicit knowledge. We discuss possible applications and present an evaluation of our approach with the retrospective, exemplary semantification of a survey. We demonstrate the utility of the SemSur ontology to answer queries about the different research contributions covered by the survey. SemSur is currently used and maintained at OpenResearch.org.
- “Cross-Lingual Ontology Enrichment Based on Multi-Agent Architecture” by Mohamed Ali, Said Fathalla, Shimaa Ibrahim, Mohamed Kholief, Yasser Hassan (Research & Innovation)
Abstract: The proliferation of ontologies and multilingual data available on the Web has motivated many researchers to contribute to multilingual and cross-lingual ontology enrichment. Cross-lingual ontology enrichment greatly facilitates ontology learning from multilingual text/ontologies in order to support collaborative ontology engineering process.This article proposes a cross-lingual ontology enrichment (CLOE) approach based on a multi-agent architecture in order to enrich ontologies from a multilingual text or ontology. This has several advantages: 1) an ontology is used to enrich another one, written in a different natural language, and 2) several ontologies could be enriched at the same time using a single chunk of text (Simultaneous Ontology Enrichment). A prototype for the proposed approach has been implemented in order to enrich several ontologies using English, Arabic and German text. Evaluation results are promising and showing that CLOE performs well in comparison with four state-of-the-art approaches.
Furthermore, we are pleased to inform that we got a talk accepted, which will be co-located with the Industry track.
Here is the accepted talk and its abstract :
- “Using the SANSA Stack on a 38 Billion Triple Ethereum Blockchain Dataset”
Abstract: SANSA is the first open source project that allows out of the box horizontally scalable analytics for large knowledge graphs. The talk will cover the main features of SANSA introducing its different layers namely, RDF, Query, Inference and Machine Learning. The talk also covers a large-scale Etherum blockchain use case at Alethio, a spinoff company of Consensys. Alethio is building an analytics dashboard that strives to provide transparency over what’s happening on the Ethereum p2p network, the transaction pool and the blockchain in order to provide “blockchain archaeology”. Their 6 billion triple dataset contains large-scale blockchain transaction data modelled as RDF according to the structure of the Ethereum ontology. Alethio chose to work with SANSA after experimenting with other existing engines. Specifically, the initial goal of Alethio was to load a 2TB EthOn dataset containing more than 6 billion triples and then performing several analytic queries on it with up to three inner joins.
SANSA has successfully provided a platform that allows running these queries.
Speaker: Hajira Jabeen
Acknowledgment
This work has received funding from the EU Horizon 2020 projects BigDataOcean (GA. 732310) and QROWD (GA no. 723088), the Marie Skłodowska-Curie action WDAqua (GA No 642795), and SPECIAL (GA. 731601).
Looking forward to seeing you at The SEMANTiCS 2018.
Short Paper accepted at ECML/PKDD 2018
 We are very pleased to announce that our group got a short paper accepted for presentation at ECML/PKDD 2018 (nectar track) : The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases will take place in the Croke Park Conference Centre, Dublin, Ireland during the 10 – 14 September 2018.
We are very pleased to announce that our group got a short paper accepted for presentation at ECML/PKDD 2018 (nectar track) : The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases will take place in the Croke Park Conference Centre, Dublin, Ireland during the 10 – 14 September 2018.
This event is the premier European machine learning and data mining conference and builds upon over 16 years of successful events and conferences held across Europe. reland is delighted to host and to bring together participants to Croke Park- one of the iconic sporting venues but also providing a world-class conference facility.
Here is the accepted paper with its abstract:
- “Deep Query Ranking for Question Answering over Knowledge Bases” by Hamid Zafar, Giulio Napolitano, and Jens Lehmann (Nectar track)
Abstract: We study question answering systems over knowledge graphs which map an input natural language question into candidate formal queries. Often, a ranking mechanism is used to discern the queries with higher similarity to the given question. Considering the intrinsic complexity of the natural language, finding the most accurate formal counter-part is a challenging task. In our recent paper, we leveraged Tree-LSTM to exploit the syntactical structure of input question as well as the candidate formal queries to compute the similarities. An empirical study shows that taking the structural information of the input question and candidate query into account enhances the performance, when compared to the baseline system.
Acknowledgment
This research was supported by EU H2020 grants for the projects HOBBIT (GA no. 688227) and WDAqua (GA no. 642795) as well as by German Federal Ministry of Education and Research (BMBF) funding for the project SOLIDE (no. 13N14456).
Looking forward to seeing you at The TPDL 2018.
Paper accepted at TPDL 2018
 We are very pleased to announce that our group got two papers accepted in TPDL 2018 : The 22nd International Conference on Theory and Practice of Digital Libraries.
We are very pleased to announce that our group got two papers accepted in TPDL 2018 : The 22nd International Conference on Theory and Practice of Digital Libraries.
The TPDL is is a well-established scientific and technical forum on the broad topic of digital libraries, bringing together researchers, developers, content providers and users in digital libraries and digital content management. The 22nd TPDL will take place in Porto, Portugal on September 10-13, 2018. The general theme of TPDL 2018 is “Digital Libraries for Open Knowledge”. 2017-2018 are considered “Year of Open” and 2018 is “the TPDL of Open”. TPDL 2018 wants to gather all the communities engaged to make the knowledge more and more open, using the available technologies, standards and infrastructures, but reflecting about the new challenges, policies and other issues to make it happen. Thus, our activities in the context of scholarly communication matched very well.
Here is the list of the accepted papers with their abstract:
- “Unveiling Scholarly Communities over Knowledge Graphs” by Sahar Vahdati, Guillermo Palma, Rahul Jyoti Nath, Maria-Esther Vidal, Christoph Lange and Sören Auer
Abstract: Knowledge graphs represent the meaning of properties of real-world entities and relationships among them in a natural way. Exploiting semantics encoded in knowledge graphs enables the implementation of knowledge-driven tasks such as semantic retrieval, query processing, and question answering, as well as solutions to knowledge discovery tasks including pattern discovery and link prediction. In this paper, we tackle the problem of knowledge discovery in scholarly knowledge graphs, i.e., graphs that integrate scholarly data, and present KORONA, a knowledge-driven framework able to unveil scholarly communities for the prediction of scholarly networks. \koronaB implements a graph partition approach and relies on semantic similarity measures to determine relatedness between scholarly entities. As a proof of concept, we built a scholarly knowledge graph with data from researchers, conferences, and papers of the Semantic Web area, and apply \koronaB to uncover co-authorship networks. Results observed from our empirical evaluation suggest that exploiting semantics in scholarly knowledge graphs enables the identification of previously unknown relations between researchers. We furthermore point out how these observations can be generalized to other scholarly entities, e.g., articles or institutions, for the prediction of other scholarly patterns, e.g., co-citations or academic collaboration.
- “Metadata Analysis of Scholarly Events on of Computer Science, Physics, Engineering and Mathematics” by Said Fathalla, Sahar Vahdati, Sören Auer and Christoph Lange
Abstract: Although digitization has significantly eased publishing, finding a relevant and suitable channel of publishing still remains challenging. To obtain a better understanding of scholarly communication in different fields and the role of scientific events, metadata of scientific events of four research communities have analyzed: Computer Science, Physics, Engineering, and Mathematics. Our transferable analysis methodology is based on descriptive statistics as well as exploratory data analysis. Metadata used in this work have been collected from the OpenResearch.org community platform and SCImago as the main resources containing metadata of scientific events in a semantically structured way. The evaluation uses metrics such as continuity, geographical and time-wise distribution, field popularity and productivity as well as event progress ratio and rankings based on the SJR indicator and h5 indices.
Looking forward to seeing you at The TPDL 2018.
SOLIDE at the BMBF Innovation Forum “Civil Security” 2018

SDA as part of SOLIDE project participated at the invitation of the Federal Ministry of Education and Research, the BMBF Innovation Forum “Civil Security” 2018 took place on 19 and 20 June 2018. The two-day conference on the framework program “Research for Civil Security” was held in the Café Moskau conference center in Berlin.
SOLIDE, as one of the funded project from BMBF has been presented during the event in the context of the session “Mission Support – Better Situation Management through Intelligent Information Acquisition”
The SOLIDE project aims to examine a new approach for efficient access to operational data using the command mission management software TecBos Command. The focus here is on the fact that information can be accessed in a natural language dialogue. For this purpose, we do research into subject-specific algorithms for filtering relevant knowledge as well as suitable data integration procedures to make the available data usable and retrievable via dialogues.
SOLIDE is a joint project of PRO DV (Dortmund), Aristech GmbH (Heidelberg) together with the research group Smart Data Analytics (SDA) of the University of Bonn and the Data Science Chair (DICE) of the University of Paderborn.
SDA contribute to the project by providing a cut edge dialog system for providing information support in emergency situations.

A BETTER project for exploiting Big Data in Earth Observation
The SANSA Stack is one of the earmarked big data analytics components to be employed in the BETTER data pipelines.
Big-data Earth observation Technology and Tools Enhancing Research and development is an EU-H2020 research and innovation project started in November 2017 to the end of October 2020.
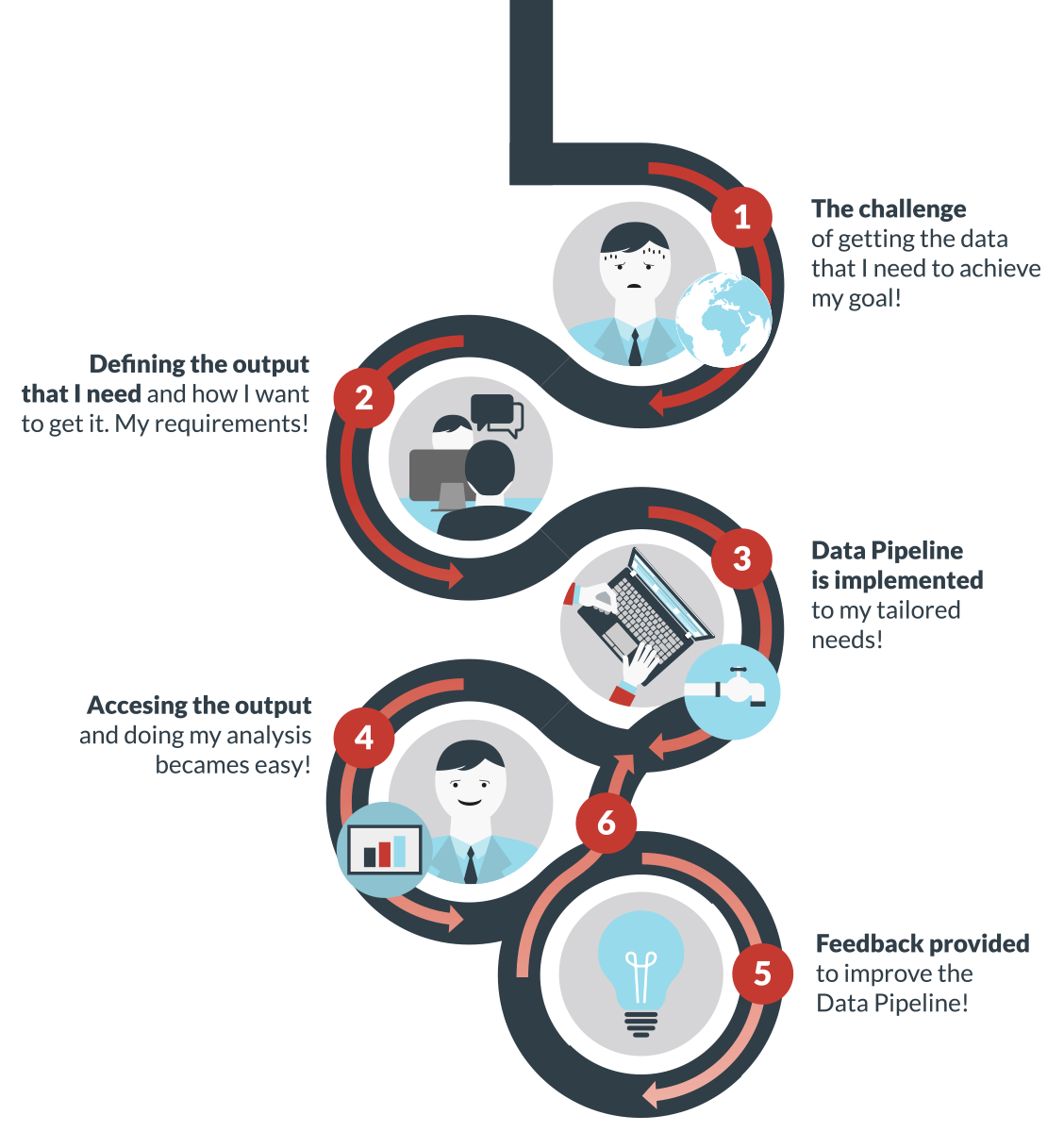 The project’s main objective is to implement Big Data solutions (denominated as Data Pipelines) based on the usage of large volumes and heterogeneous Earth Observation datasets. This should help addressing key Societal Challenges, so the users can focus on the analysis of the extraction of the potential knowledge within the data and not on the processing of the data itself.
The project’s main objective is to implement Big Data solutions (denominated as Data Pipelines) based on the usage of large volumes and heterogeneous Earth Observation datasets. This should help addressing key Societal Challenges, so the users can focus on the analysis of the extraction of the potential knowledge within the data and not on the processing of the data itself.
To achieve that, BETTER is improving the way Big Data service developers interact with end-users. After defining the challenges, the promoters validate the pipelines requirements and co-design the solution with a dedicated development team in a workshop. During the implementation, promoters can continuously test and validate the pipelines. Later, the implemented pipelines will be used by the public in the scope of Hackathons, enabling the use of specific solutions in other areas and the collection of additional user feedback. www.ec-better.eu
SUBSCRIBE HERE for major project updates.
SANSA 0.4 (Semantic Analytics Stack) Released
We are happy to announce SANSA 0.4 – the fourth release of the Scalable Semantic Analytics Stack. SANSA employs distributed computing via Apache Spark and Flink in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: http://sansa-stack.net/downloads-usage/
- ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:
- Reading and writing RDF files in N-Triples, Turtle, RDF/XML, N-Quad format
- Reading OWL files in various standard formats
- Support for multiple data partitioning techniques
- SPARQL querying via Sparqlify
- Graph-parallel querying of RDF using SPARQL (1.0) via GraphX traversals (experimental)
- RDFS, RDFS Simple, OWL-Horst, EL (experimental) forward chaining inference
- Automatic inference plan creation (experimental)
- RDF graph clustering with different algorithms
- Terminological decision trees (experimental)
- Anomaly detection (beta)
- Knowledge graph embedding approaches: TransE (beta), DistMult (beta)
Noteworthy changes or updates since the previous release are:
- Parser performance has been improved significantly e.g. DBpedia 2016-10 can be loaded in <100 seconds on a 7 node cluster
- Support for a wider range of data partitioning strategies
- A better unified API across data representations (RDD, DataFrame, DataSet, Graph) for triple operations
- Improved unit test coverage
- Improved distributed statistics calculation (see ISWC paper)
- Initial scalability tests on 6 billion triple Ethereum blockchain data on a 100 node cluster
- New SPARQL-to-GraphX rewriter aiming at providing better performance for queries exploiting graph locality
- Numeric outlier detection tested on DBpedia (en)
- Improved clustering tested on 20 GB RDF data sets
Deployment and getting started:
- There are template projects for SBT and Maven for Apache Spark as well as for Apache Flink available to get started.
- The SANSA jar files are in Maven Central i.e. in most IDEs you can just search for “sansa” to include the dependencies in Maven projects.
- Example code is available for various tasks.
- We provide interactive notebooks for running and testing code via Docker.
We want to thank everyone who helped to create this release, in particular the projects Big Data Europe, HOBBIT, SAKE, Big Data Ocean, SLIPO, QROWD, BETTER, BOOST and SPECIAL.
Spread the word by retweeting our release announcement on Twitter. For more updates, please view our Twitter feed and consider following us.
Greetings from the SANSA Development Team
Papers accepted at ISWC 2018
 We are very pleased to announce that our group got 3 papers accepted for presentation at ISWC 2018: The 17th International Semantic Web Conference, which will be held on October 8 – 12, 2018 in Monterey, California, USA.
We are very pleased to announce that our group got 3 papers accepted for presentation at ISWC 2018: The 17th International Semantic Web Conference, which will be held on October 8 – 12, 2018 in Monterey, California, USA.
The International Semantic Web Conference (ISWC) is the premier international forum where Semantic Web / Linked Data researchers, practitioners, and industry specialists come together to discuss, advance, and shape the future of semantic technologies on the web, within enterprises and in the context of the public institution.
Here is the list of the accepted papers with their abstract:
- “EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs” by Mohnish Dubey, Debayan Banerjee, Debanjan Chaudhuri and Jens Lehmann (Research Track)
Abstract: Many question answering systems over knowledge graphs rely on entity and relation linking components in order to connect the natural language input to the underlying knowledge graph. Traditionally, entity linking and relation linking has been performed either as a dependent, sequential tasks or as independent, parallel tasks. In this paper, we propose a framework called EARL, which performs entity linking and relation linking as a joint task. EARL implements two different solution strategies for which we provide a comparative analysis in this paper: The first strategy is a formalization of the joint entity and relation linking tasks as an instance of the Generalised Travelling Salesman Problem (GTSP). In order to be computationally feasible, we employ approximate GTSP solvers. The second strategy uses machine learning in order to exploit the connection density between nodes in the knowledge graph. It relies on three base features and re-ranking steps in order to predict entities and relations. We compare the strategies and evaluate them on a dataset with 5000 questions. Both strategies significantly outperform the current state-of-the-art approaches for entity and relation linking.
- “DistLODStats: Distributed Computation of RDF Dataset Statistics” by Gezim Sejdiu, Ivan Ermilov, Jens Lehmann and Mohamed Nadjib Mami (Resources Track)
Abstract: Over the last years, the Semantic Web has been growing steadily. Today, we count more than 10,000 datasets made available online following Semantic Web standards. Nevertheless, many applications, such as data integration, search, and interlinking, may not take the full advantage of the data without having a priori statistical information about its internal structure and coverage. In fact, there are already a number of tools, which offer such statistics, providing basic information about RDF datasets and vocabularies. However, those usually show severe deficiencies in terms of performance once the dataset size grows beyond the capabilities of a single machine. In this paper, we introduce a software library for statistical calculations of large RDF datasets, which scales out to clusters of machines. More specifically, we describe the first distributed in-memory approach for computing 32 different statistical criteria for RDF datasets using Apache Spark. The preliminary results show that our distributed approach improves upon a previous centralized approach we compare against and provides approximately linear horizontal scale-up. The criteria are extensible beyond the 32 default criteria, is integrated into the larger SANSA framework and employed in at least four major usage scenarios beyond the SANSA community.
- “Synthesizing Knowledge Graphs from web sources with the MINTE+ framework” by Diego Collarana, Mikhail Galkin, Christoph Lange, Simon Scerri, Sören Auer and Maria-Esther Vidal (In-Use Track)
Abstract: Institutions from different domains require the integration of data coming from heterogeneous Web sources. Typical use cases include Knowledge Search, Knowledge Building, and Knowledge Completion. We report on the implementation of the RDF Molecule-Based Integration Framework MINTE+ in three domain-specific applications: Law Enforcement, Job Market Analysis, and Manufacturing. The use of RDF molecules as data representation and a core element in the framework gives MINTE+ enough flexibility to synthesize knowledge graphs in different domains. We first describe the challenges in each domain-specific application, then the implementation and configuration of the framework to solve the particular problems of each domain. We show how the parameters defined in the framework allow to tune the integration process with the best values according to each domain. Finally, we present the main results, and the lessons learned from each application.
Acknowledgment
This work has received funding from the EU Horizon 2020 projects BigDataEurope (GA no. 644564) and QROWD (GA no. 723088), the Marie Skłodowska-Curie action WDAqua(GA No 642795), and HOBBIT (GA. 688227), and (project SlideWiki, grant no. 688095), and the German Ministry of Education and Research (BMBF) in the context of the projects LiDaKrA (Linked-Data-basierte Kriminalanalyse, grant no. 13N13627) and InDaSpacePlus (grant no. 01IS17031).
Looking forward to seeing you at The ISWC 2018.
Paper accepted at GRADES 2018 workshop at SIGMOD / PODS
![]()
We are very pleased to announce that our group got 1 paper accepted for presentation at the GRADES workshop at SIGMOS / PODS 2018: The International ACM International Conference on Management of Data, which will be held in Houston, TX, USA, on June 10th – June 15th, 2018.
The annual ACM SIGMOD/PODS Conference is a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results and to exchange techniques, tools, and experiences. The conference includes a fascinating technical program with research and industrial talks, tutorials, demos, and focused workshops. It also hosts a poster session to learn about innovative technology, an industrial exhibition to meet companies and publishers, and a careers-in-industry panel with representatives from leading companies.
The focus of the GRADES 2018 workshop is the application areas, usage scenarios and open challenges in managing large-scale graph-shaped data. The workshop is a forum for exchanging ideas and methods for mining, querying and learning with real-world network data, developing new common understandings of the problems at hand, sharing of data sets and benchmarks where applicable, and leveraging existing knowledge from different disciplines. Additionally, considering specific techniques (e.g., algorithms, data/index structures) in the context of the systems that implement them, rather than describing them in isolation, GRADES-NDA aims to present technical contributions inside the graph, RDF and other data management systems on graphs of a large size.
Here is the accepted paper with its abstract:
- “Two for One — Querying Property Graphs using SPARQL via GREMLINATOR” by Harsh Thakkar, Dharmen Punjani, Jens Lehmann and Sören Auer
Abstract: In the past decade Knowledge graphs have become very popular and frequently rely on the Resource Description Framework (RDF) or Property Graphs (PG) as their data models. However, the query languages for these two data models – SPARQL for RDF and the PG traversal language Gremlin – are lacking basic interoperability. In this demonstration paper, we present Gremlinator, the first translator from SPARQL – the W3C standardized language for RDF – to Gremlin – a popular property graph traversal language. Gremlinator translates SPARQL queries to Gremlin path traversals for executing graph pattern matching queries over graph databases. This allows a user, who is well versed in SPARQL, to access and query a wide variety of Graph databases avoiding the steep learning curve for adapting to a new Graph Query Language (GQL). Gremlin is a graph computing system-agnostic traversal language (covering both OLTP graph databases and OLAP graph processors), making it a desirable choice for supporting interoperability for querying Graph databases. Gremlinator is planned to be released as an Apache TinkerPop plugin in the upcoming releases.
Acknowledgment
This work has received funding from the EU H2020 R&I programme for the Marie Skłodowska-Curie action WDAqua (GA No 642795).
Looking forward to seeing you at The GRADES 2018.