
Paper Accepted at EACL21
We are happy to announce that we got a paper accepted for presentation at EACL21 (European Chapter of the ACL). The European Chapter of the ACL (EACL) is the primary professional association for computational linguistics in Europe.
Here is the pre-print of the accepted paper with its abstract:
Conversational Question Answering over Knowledge Graphs with Transformer and Graph Attention NetworksBy Endri Kacupaj, Joan Plepi, Kuldeep Singh, Harsh Thakkar,Jens Lehmann, and Maria Maleshkova.
Abstract
This paper addresses the task of (complex) conversational question answering over a knowledge graph. For this task, we propose LASAGNE (muLti-task semAntic parSing with trAnsformer and Graph atteNtion nEtworks). It is the first approach, which employs a transformer architecture extended with Graph Attention Networks for multi-task neural semantic parsing. LASAGNE uses a transformer model for generating the base logical forms, while the Graph Attention model is used to exploit correlations between (entity) types and predicates to produce node representations. LASAGNE also includes a novel entity recognition module which detects, links, and ranks all relevant entities in the question context. We evaluate LASAGNE on a standard dataset for complex sequential question answering, on which it outperforms existing baseline averages on all question types. Specifically, we show that LASAGNE improves the F1-score on eight out of ten question types; in some cases, the increase in F1-score is more than 20% compared to the state of the art.Paper Accepted at PAKDD 2021
We are happy to announce that we got a paper accepted for presentation at PAKDD 2021 (Pacific-Asia Conference on Knowledge Discovery and Data Mining). PAKDD is one of the longest established and leading international conferences in the areas of data mining and knowledge discovery. It provides an international forum for researchers and industry practitioners to share their new ideas, original research results, and practical development experiences from all KDD related areas, including data mining, data warehousing, machine learning, artificial intelligence, databases, statistics, knowledge engineering, visualization, decision-making systems, and the emerging applications.
Here is the pre-print of the accepted paper with its abstract:
Loss-aware Pattern Inference: A Correction on the Wrongly Claimed Limitations of Embedding ModelsBy Mojtaba Nayyeri, Chengjin Xu, Yadollah Yaghoobzadeh, Sahar Vahdati,Mirza Mohtashim Alam,Hamed Shariat Yazdi and Jens Lehmann.
Abstract
Embedding knowledge graphs (KGs) into a low dimensional space has become an active research domain which is broadly utilized in many of the AI-based tasks, especially link prediction. One of the crucial aspects is the extent to which a KG embedding model (KGE) is capable to model and infer various relation patterns, such as symmetry/antisymmetry, inversion, and composition. Each embedding model is highly affected in the optimization of embedding vectors by their loss function which consequently affects the inference of relational patterns. However, most existing methods failed to consider this aspect in their inference capability. In this paper, we show that disregarding loss functions results in inaccurate or even wrong interpretation from the capability of the models. We provide deep theoretical investigations of the already existing KGE models on the example of the TransE model. To the best of our knowledge, so far, this has not been comprehensively investigated. We show that by a proper selection of the loss function for training a KGE e.g., TransE, the main inference limitations are mitigated. The provided theories together with the experimental results confirm the importance of loss functions for training KGE models and their performance.SANSA 0.8.0 RC1 (Semantic Analytics Stack) Released
The Smart Data Analytics group [1] is happy to announce the candidate release (0.8.0 RC1) for SANSA Scalable Semantic Analytics Stack. SANSA employs distributed computing via Apache Spark in order to allow scalable machine learning, inference, and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:
- Reading and writing RDF files in N-Triples, Turtle, RDF/XML, N-Quad format
- Reading OWL files in various standard formats
- SPARQL querying via Sparqlify, Ontop and Tensors
- RDFS, RDFS Simple and OWL-Horst forward chaining inference
Noteworthy changes and updates since the previous release are:
- Support for Ontop Based Query Engine over RDF.
- Distributed Trig/Turtle record reader.
- Support to write out RDDs of OWL axioms in a variety of formats.
- Distributed Data Summaries with ABstraction and STATistics (ABSTAT).
- Configurable mapping of RDD of triples dataframes.
- Initial support for RDD of Graphs and Datasets, executing queries on each entry and aggregating over the results.
- Sparql Transformer for ML-Pipelines.
- Autosparql Generation for Feature Extraction.
- Distributed Feature-based Semantic Similarity Estimations.
- Added a common R2RML abstraction layer for Ontop, Sparqlify, and possible future query engines.
- Consolidated SANSA layers into a single GIT repository.
- Retired the support for Apache Flink.
We look forward to your comments on the new features to make them permanent in our upcoming release 0.8.
Kindly note that the candidate is not in the Maven Central, please follow the readme.
We want to thank everyone who helped to create this release, in particular the projects supporting us: PLATOON, BETTER, BOOST, SPECIAL, Simple-ML, LAMBDA, ML-win, CALLISTO, OpertusMundi, & Cleopatra.
Greetings from the SANSA Development Team
SANSA 0.8.0 Release
The Smart Data Analytics group (http://sda.tech) is happy to announce SANSA 0.8.0 RC – the eighth release (candidate) of the Scalable Semantic Analytics Stack. SANSA employs distributed computing using Apache Spark in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
We look forward to your comments on the new features to make them permanent in our upcoming release.
Kindly note that the candidate is not in the Maven Central, please follow the readme.
Website: http://sansa-stack.net
GitHub: https://github.com/SANSA-Stack
Download: https://github.com/SANSA-Stack/SANSA-Stack/releases
In this release candidate, we have included:
- Integrated Ontop as a new SPARQL engine
- Improved SPARQL query API
- Distributed Trig/Turtle record reader
- Support to write out RDDs of OWL axioms in a variety of formats.
- Distributed Data Summaries with ABstraction and STATistics (ABSTAT)
- Configurable mapping of RDD of triples dataframes
- Initial support for RDD of Graphs and Datasets, executing queries on each entry and aggregating over the results
- Sparql Transformer for ML-Pipelines
- Autosparql Generation for Feature Extraction
- Distributed Feature based Semantic Similarity Estimations
- Added a common R2RML abstraction layer for Ontop, Sparqlify and possible future query engines
- Consolidated SANSA layers into a single GIT repository
- Retired the support for Apache Flink
View this announcement on Twitter and SANSA blog:
PhD Viva: “Strategies for a Semantified Uniform Access to Large and Heterogeneous Data Sources” Mohamed Nadjib Mami
On Thursday 28th of January 2021, I have successfully defended my PhD thesis entitled “Strategies for a Semantified Uniform Access to Large and Heterogeneous Data Sources”. The research work focuses on enabling the uniform querying of large and heterogeneous data sources (using SPARQL). Two directions were explored: (1) Physical Big Data Integration, where all input data is converted into RDF data model, (2) Virtual Big Data Integration, where input data remains in its original form and accessed in an ad hoc manner (aka Semantic Data Lake). In the latter, relevant data is internally and virtually represented under RDF data model. State-of-the-art Big Data technologies, e.g., Apache Spark, Presto, Cassandra, MongoDB, were incorporated.
Congratulations to @MohamedNadjMAMI who defended his PhD thesis on semantified uniform access to large heterogenous data sources today! Mohamed is a creator of the “semantic data lake” concept and has done substantial work on query translation & virtual+physical data integration. pic.twitter.com/fjzP77bnRd
— Jens Lehmann (@JLehmann82) January 28, 2021
Abstract
The remarkable advances achieved in both research and development of Data Management as well as the prevalence of high-speed Internet and technology in the last few decades have caused unprecedented data avalanche. Large volumes of data manifested in a multitude of types and formats are being generated and becoming the new norm. In this context, it is crucial to both leverage existing approaches and propose novel ones to overcome this data size and complexity, and thus facilitate data exploitation. In this thesis, we investigate two major approaches to addressing this challenge: Physical Data Integration and Logical Data Integration. The specific problem tackled is to enable querying large and heterogeneous data sources in an ad hoc manner.
In the Physical Data Integration, data is physically and wholly transformed into a canonical unique format, which can then be directly and uniformly queried. In the Logical Data Integration, data remains in its original format and form and a middleware is posed above the data allowing to map various schemata elements to a high-level unifying formal model. The latter enables the querying of the underlying original data in an ad hoc and uniform way, a framework which we call Semantic Data Lake, SDL. Both approaches have their advantages and disadvantages. For example, in the former, a significant effort and cost are devoted to pre-processing and transforming the data to the unified canonical format. In the latter, the cost is shifted to the query processing phases, e.g., query analysis, relevant source detection and results reconciliation.
In this thesis we investigate both directions and study their strengths and weaknesses. For each direction, we propose a set of approaches and demonstrate their feasibility via a proposed implementation. In both directions, we appeal to Semantic Web technologies, which provide a set of time-proven techniques and standards that are dedicated to Data Integration. In the Physical Integration, we suggest an end-to-end blueprint for the semantification of large and heterogeneous data sources, i.e., physically transforming the data to the Semantic Web data standard RDF (Resource Description Framework). A unified data representation, storage and query interface over the data are suggested. In the Logical Integration, we provide a description of the SDL architecture, which allows querying data sources right on their original form and format without requiring a prior transformation and centralization. For a number of reasons that we detail, we put more emphasis on the virtual approach. We present the effort behind an extensible implementation of the SDL, called Squerall, which leverages state-of-the-art Semantic and Big Data technologies, e.g., RML (RDF Mapping Language) mappings, FnO (Function Ontology) ontology, and Apache Spark. A series of evaluation is conducted to evaluate the implementation along with various metrics and input data scales. In particular, we describe an industrial real-world use case using our SDL implementation. In a preparation phase, we conduct a survey for the Query Translation methods in order to back some of our design choices.
Thesis
The thesis is available online at: <https://bonndoc.ulb.uni-bonn.de/xmlui/handle/20.500.11811/8925>.
CLEOPATRA
In the following, we summarize the activities of the last twelve months within the CLEOPATRA (Cross-lingual Event-centric Open Analytics Research Academy) project in which we participate.
Despite the challenges of running an international research project during a period of restricted mobility and access, the CLEOPATRA project team have enjoyed some major successes over the last twelve months. Our fourteen Early Stage Researchers (ESR) have shown remarkable ability to adapt, innovate and collaborate. They have worked together online, across different countries and time zones, to build tools and design methods for studying the digital traces of major global events. In April 2020, a hackathon and Research & Development week were quickly reorganised to be delivered virtually. Working in teams, the ESRs developed demonstrators to address such questions as how to analyse online media over time and in multiple (often under-resourced) languages. There was further opportunity to work on the demonstrators, and to develop new research ideas, at a Learning week in June 2020, held in conjunction with the University of Amsterdam Digital Methods Summer School. In January 2021, the ESRs organised a second virtual hackathon and Research & Development week, which resulted in the publication of an updated Open Event Knowledge Graph (OEKG). The OEKG is one of the key resources developed by the project, and currently contains information about more than a million events in 15 European languages. This is a unique resource which will transform our understanding of how transitional social, cultural and political events play out online. All of these activities have led to the continuation and formation of new and promising research collaborations, which we hope to see bear fruit in the coming months.
The ESRs and project beneficiaries have also been busy organising and attending conferences. In June 2020, an International Workshop on Cross-lingual Event-centric Open Analytics was held online, in association with the 17th Extended Semantic Web Conference. The award for the best paper delivered at the workshop was given to a team led by CLEOPATRA ESR, Golsa Tahmasebzadeh, working with Sherzod Hakimov, Eric Müller-Budack and Ralph Ewerth. A second international workshop will be held in April 2021, this time in association with the Web Conference. The project has been presented at numerous online conferences, in such diverse fields as the semantic web, artificial intelligence, web archive studies and spoken-language technologies. Publications arising from these events and other activities include blog posts, open datasets and no fewer than 17 conference proceedings and journal articles.
Information about all of these activities, and the various open resources that have been developed by the project team, can be found on the CLEOPATRA website, and you can follow us on Twitter @Cleopatra_ITN for the latest news and updates.
Paper Accepted at KEOD
We are happy to announce that we got two papers accepted for presentation at KEOD 20 (International Conference on Knowledge Engineering and Ontology Development). Knowledge Engineering (KE) refers to all technical, scientific and social aspects involved in building, maintaining and using knowledge-based systems. KE is a multidisciplinary field, bringing in concepts and methods from several computer science domains such as artificial intelligence, databases, expert systems, decision support systems and information systems.
Here is the pre-print of the accepted paper with its abstract:
- A Distributed Approach for Parsing Large-Scale OWL Datasets
Heba Mohamed, Said Fathalla, Jens Lehmann, and Hajira Jabeen.Abstract
Ontologies are widely used in many diverse disciplines, including but not limited to biology, geology, medicine, geography and scholarly communications. In order to understand the axiomatic structure of the ontologies in OWL/XML syntax, an OWL/XML parser is needed. Several research efforts offer such parsers; however, these parsers usually show severe limitations as the dataset size increases beyond a single machine’s capabilities. To meet increasing data requirements, we present a novel approach, i.e., DistOWL, for parsing large-scale OWL/XML datasets in a cost-effective and scalable manner. DistOWL is implemented using an in-memory and distributed framework, i.e., Apache Spark. While the application of the parser is rather generic, two use cases are presented for the usage of DistOWL. The Lehigh University Benchmark (LUBM) has been used for the evaluation of DistOWL. The preliminary results show that DistOWL provides a linear scale-up compared to prior centralized approaches. - Semantic Representation of Physics Research Data
Aysegul Say, Said Fathalla, Sahar Vahdati, Jens Lehmann, and Sören Auer.Abstract
Improvements in web technologies and artificial intelligence enable novel, more data-driven research practices for scientists. However, scientific knowledge generated from data-intensive research practices is disseminated with unstructured formats, thus hindering the scholarly communication in various respects. The traditional document-based representation of scholarly information hampers the reusability of research contributions. To address this concern, we developed the Physics Ontology (PhySci) to represent physics-related scholarly data in a machine-interpretable format. PhySci facilitates knowledge exploration, comparison, and organization of such data by representing it as knowledge graphs. It establishes a unique conceptualization to increase the visibility and accessibility to the digital content of physics publications. We present the iterative design principles by outlining a methodology for its development and applying three different evaluation approaches: data-driven and criteria-based evaluation, as well as ontology testing.
5* Knowledge Graph Embeddings with Projective Transformations Accepted At AAAI21
We are thrilled to announce that we got a paper accepted for presentation at AAAI Conference on Artificial Intelligence (AAAI-21). The purpose of the AAAI conference is to promote research in artificial intelligence (AI) and scientific exchange among AI researchers, practitioners, scientists, and engineers in affiliated disciplines.
Here is the pre-print of the accepted paper with its abstracts:
- 5* Knowledge Graph Embeddings with Projective Transformations
By Mojtaba Nayyeri,Sahar Vahdati,Can Aykul, and Jens LehmannAbstract
Performing link prediction using knowledge graph embedding (KGE) models is a popular approach for knowledge graph completion. Such link predictions are performed by measuring the likelihood of links in the graph via a transformation function that maps nodes via edges into a vector space. Since the complex structure of the real world is reflected in multi-relational knowledge graphs, the transformation functions need to be able to represent this complexity. However, most of the existing transformation functions in embedding models have been designed in Euclidean geometry and only cover one or two simple transformations. Therefore, they are prone to underfitting and limited in their ability to embed complex graph structures. The area of projective geometry, however, fully covers inversion, reflection, translation, rotation, and homothety transformations. We propose a novel KGE model, which supports those transformations and subsumes other state-of-the-art models. The model has several favorable theoretical properties and outperforms existing approaches on widely used link prediction benchmarks.
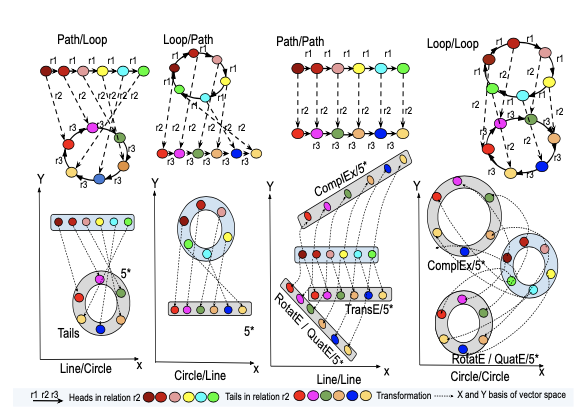
5*E covers 5 transformation types: Translation, Rotation, Inversion, Reflection, and Homothety, and covers 5 transformation functions: Hyperbolic, Parabolic, Loxodromic, Elliptic and Circular as shown in the following figure created by a Riemann sphere.

5*E applies the following steps to measure the plausibility of a triple (h,r,t):
- Mapping head node embedding (h) from complex plane to Riemann sphere using stereographic projection
- Moving the sphere using a relation specific transformation (r.)
- Mapping the transformed head (h) from Riemann sphere to the complex plane to meet tail embedding (t)
This way, our model is able to capture complex structures in the subgraphs of a knowledge graph, for example where a path of nodes is connected to a loop through multiple relations:
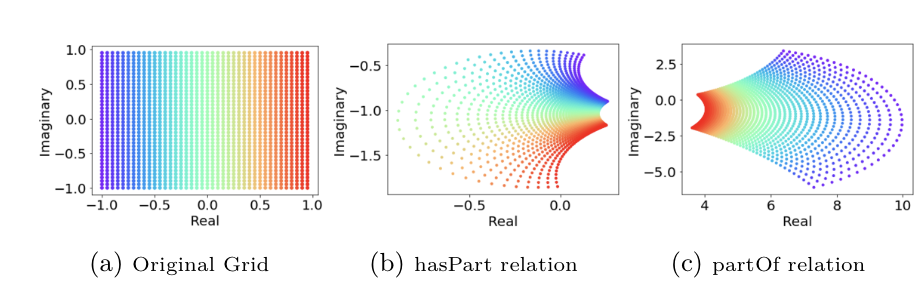
Starting from a plain grid, we can visualise how different transformations evolve in capturing different relational patterns, in this case the inverse relation hasPart and partOf:
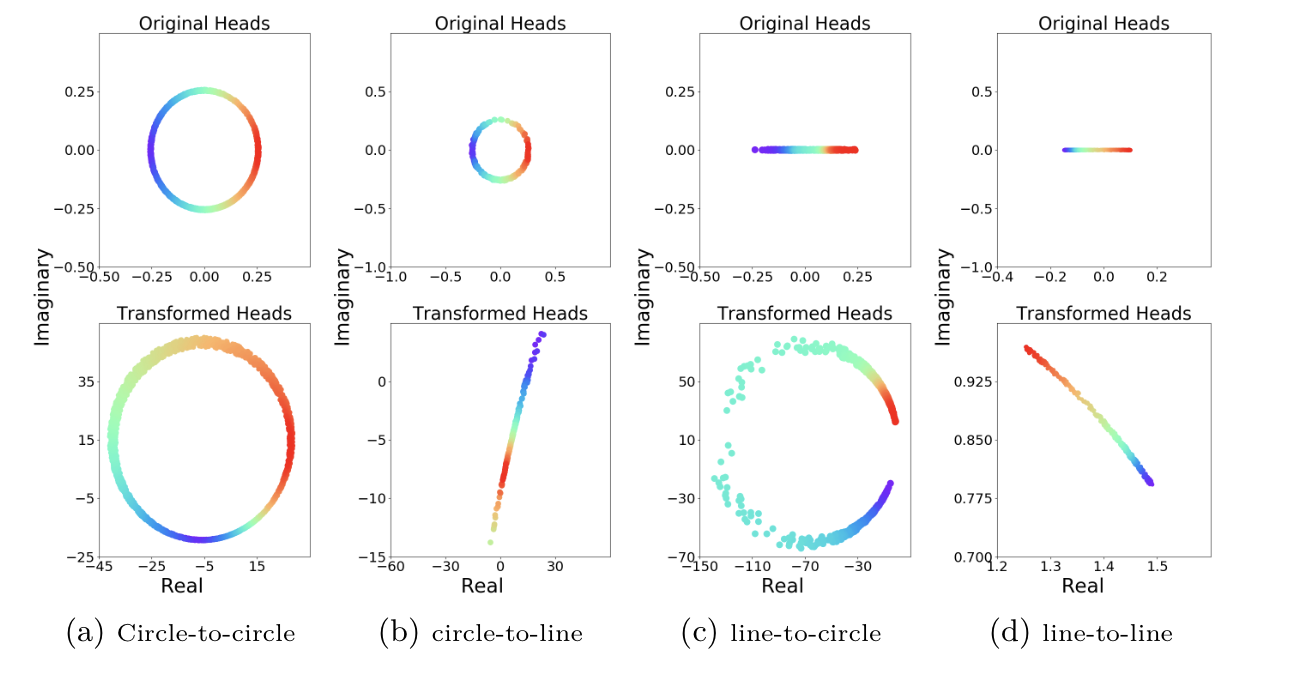
5*E is able to preserve various graph structures (paths, loops) and relational patterns in the knowledge graph embedding space:
Papers Accepted at WI-IAT 2020
We are happy to announce that we got two accepted for presentation at WI-IAT 20 (International Joint Conference on Web Intelligence and Intelligent Agent Technology). WI-IAT 20 provides a premier international forum to bring together researchers and practitioners from diverse fields for presentation of original research results, as well as exchange and dissemination of innovative and practical development experiences on Web intelligence and intelligent agent technology research and applications.
Here is the pre-print of the accepted paper with its abstract:
-
Multilingual Ontology Merging Using Cross-lingual Matching
By Shimaa Ibrahim, Said Fathalla, Jens Lehmann, and Hajira Jabeen.Abstract
With the growing amount of multilingual data on the Semantic Web, several ontologies (in different natural languages) have been developed to model the same domain. Creating multilingual ontologies by merging such monolingual ones is important to promote semantic interoperability among different ontologies in different natural languages. This is a step towards achieving the multilingual Semantic Web. In this paper, we propose MULON, an approach for merging monolingual ontologies in different natural languages producing a multilingual ontology. MULON approach comprises three modules; Preparation Module, Merging Module, and Assessment Module. We consider both classes and properties in the merging process. We present three real-world use cases describing the usability of the MULON approach in different domains. We assess the quality of the merged ontologies using a set of predefined assessment metrics. MULON has been implemented using Scala and Apache Spark under an open-source license. We have compared our cross-lingual matching results with the results from the Ontology Alignment Evaluation Initiative (OAEI 2019). MULON has achieved relatively high precision, recall, and F-measure in comparison to three state-of-the-art approaches in the matching process and significantly higher coverage without any redundancy in the merging process. -
OWLStats: Distributed Computation of OWL Dataset Statistics
By Heba Mohamed, Said Fathalla, Jens Lehmann, and Hajira Jabeen.Abstract
Nowadays, ontologies are used in various application areas, involving Artificial Intelligence, Natural Language Processing, Data Integration, and Knowledge Management. It is essential to know the internal structure, distribution, and coherence of the published datasets to make it easier for reuse, interlink, integrate, infer, or query. Therefore, there is a pressing need to obtain a clear view of OWL datasets became more prevalent. In this paper, we present OWLStats, a software component for computing statistical information about large scale OWL datasets in a distributed manner. We present the primary distributed in-memory approach for computing 32 different statistical criteria for OWL datasets utilizing Apache Spark, which can scale horizontally to a cluster of machines. OWLStats has been integrated into the SANSA framework. The preliminary results prove that OWLStats is linearly scalable in terms of data scalability.
Papers Accepted at COLING 2020
We are very pleased to announce that we got three papers accepted for presentation at COLING 2020 (International Conference on Computational Linguistics). The first COLING was held in New York in 1965, with the last iteration in Santa Fe, USA, in 2018. Throughout its history, COLING has brought together researchers from across the field of Computational Linguistics. COLING’2020 continues this tradition and thus welcomes papers on all topics related to both natural language and computation, with the expectation that all papers will include linguistic insight.
Here are the pre-prints of the accepted papers with their abstracts:
- Language Model Transformers as Evaluators for Open-domain Dialogues
By Rostislav Nedelchev, Ricardo Usbeck , and Jens Lehmann.Abstract
Computer-based systems for communication with humans are a cornerstone of AI research since the 1950s. So far, the most effective way to assess the quality of the dialogues produced by these systems is to use resource-intensive manual labor instead of automated means. In this work, we investigate whether language models (LM) based on transformer neural networks can indicate the quality of a conversation. In a general sense, language models are methods that learn to predict one or more words based on an already given context. Due to their unsupervised nature, they are candidates for efficient, automatic indication of dialogue quality. We demonstrate that human evaluators have a positive correlation between the output of the language models and scores. We also provide some insights into their behavior and inner-working in a conversational context. - Knowledge Graph Embeddings in Geometric Algebras
By Chengjin Xu, Mojtaba Nayyeri, Yung-Yu Chen, and Jens Lehmann.Abstract
Knowledge graph (KG) embedding aims at embedding entities and relations in a KG into a low dimensional latent representation space. Existing KG embedding approaches model entities and relations in a KG by utilizing real-valued , complex-valued, or hypercomplex-valued (Quaternion or Octonion) representations, all of which are subsumed into a geometric algebra. In this work, we introduce a novel geometric algebra-based KG embedding framework, GeomE, which utilizes multivector representations and the geometric product to model entities and relations. Our framework subsumes several state-of-the-art KG embedding approaches and is advantageous with its ability of modeling various key relation patterns, including (anti-)symmetry, inversion and composition, rich expressiveness with higher degree of freedom as well as good generalization capacity. Experimental results on multiple benchmark knowledge graphs show that the proposed approach outperforms existing state-of-the-art models for link prediction. - TeRo: A Time-aware Knowledge Graph Embedding via Temporal Rotation
By Chengjin Xu, Mojtaba Nayyeri, Fouad Alkhoury, Hamed Shariat Yazdi, and Jens Lehmann.Abstract
In the last few years, there has been a surge of interest in learning representations of entities and relations in knowledge graph (KG). However, the recent availability of temporal knowledge graphs (TKGs) that contain time information for each fact created the need for reasoning over time in such TKGs. In this regard, we present a new approach of TKG embedding, TeRo, which defines the temporal evolution of entity embedding as a rotation from the initial time to the current time in the complex vector space. Specially, for facts involving time intervals, each relation is represented as a pair of dual complex embeddings to handle the beginning and the end of the relation, respectively. We show our proposed model overcomes the limitations of the existing KG embedding models and TKG embedding models and has the ability of learning and inferring various relation patterns over time. Experimental results on three different TKGs show that TeRo significantly outperforms existing state-of-the-art models for link prediction. In addition, we analyze the effect of time granularity on link prediction over TKGs, which as far as we know has not been investigated in previous literature.