A Corpus for Complex Question Answering over Knowledge Graphs
A Corpus for Complex Question Answering over Knowledge GraphsDataset Generation Workflow
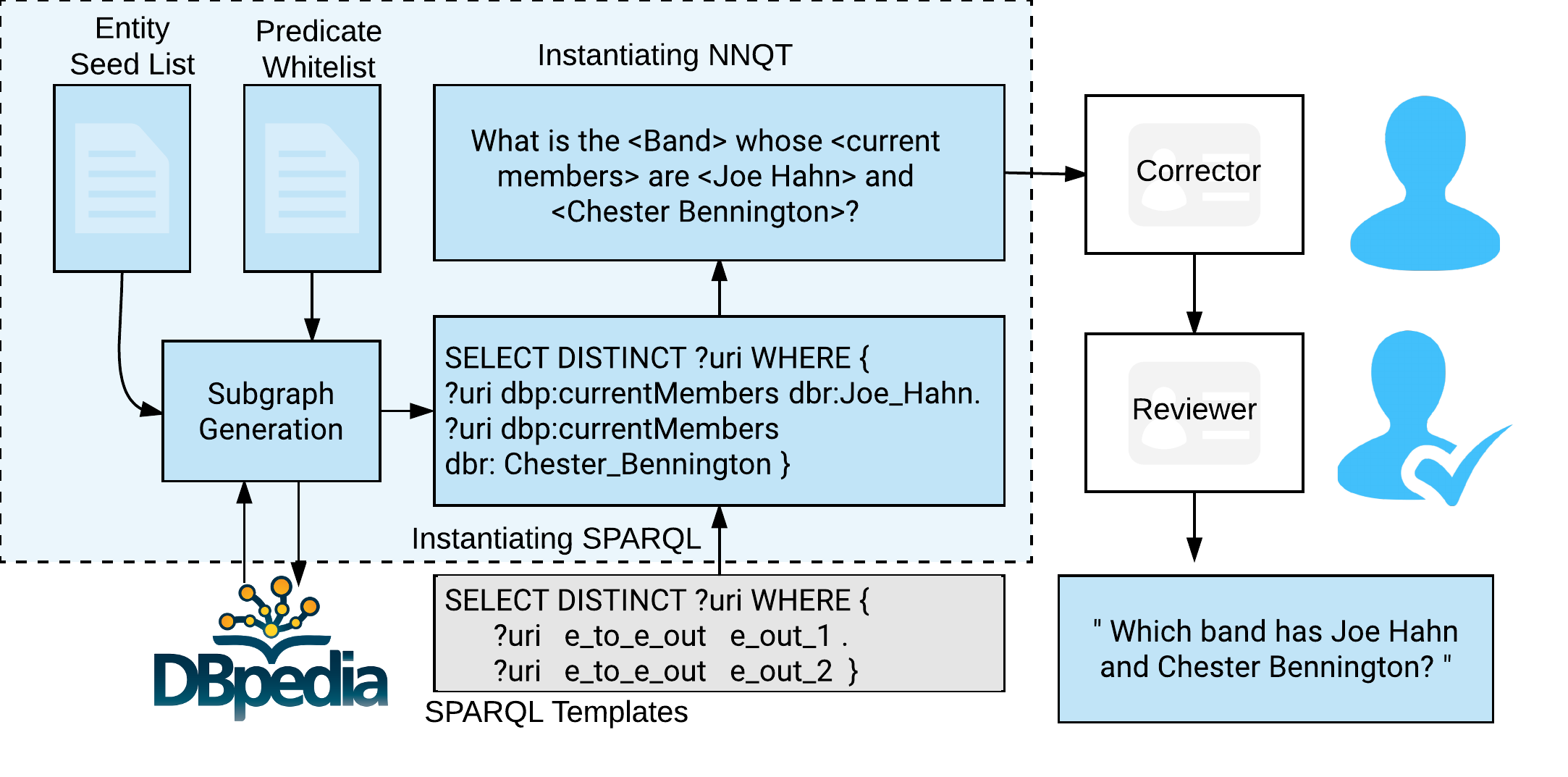
Using a list of seed entities, and filtering by a predicate whitelist, we generate subgraphs of DBpedia to instantiate SPARQL templates, thereby generating valid SPARQL queries. These SPARQL queries are then used to instantiate NNQTs and generate questions (which are often grammatically incorrect). These questions are manually corrected and paraphrased. This is then reviewed and optionally edited by the reviewer