LC-QuAD 2.0: A large dataset for complex question answering over Wikidata and DBpedia
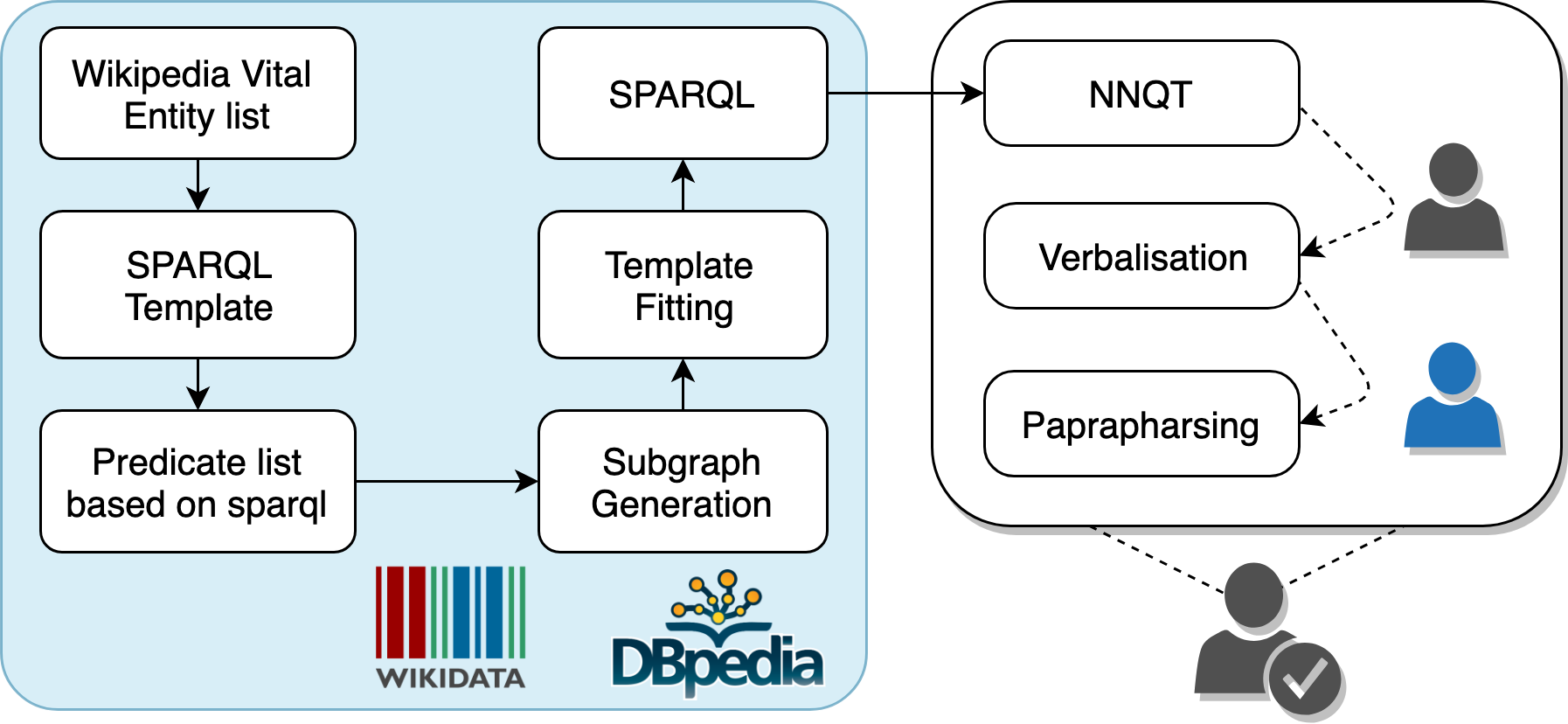
Dataset Generation Workflow
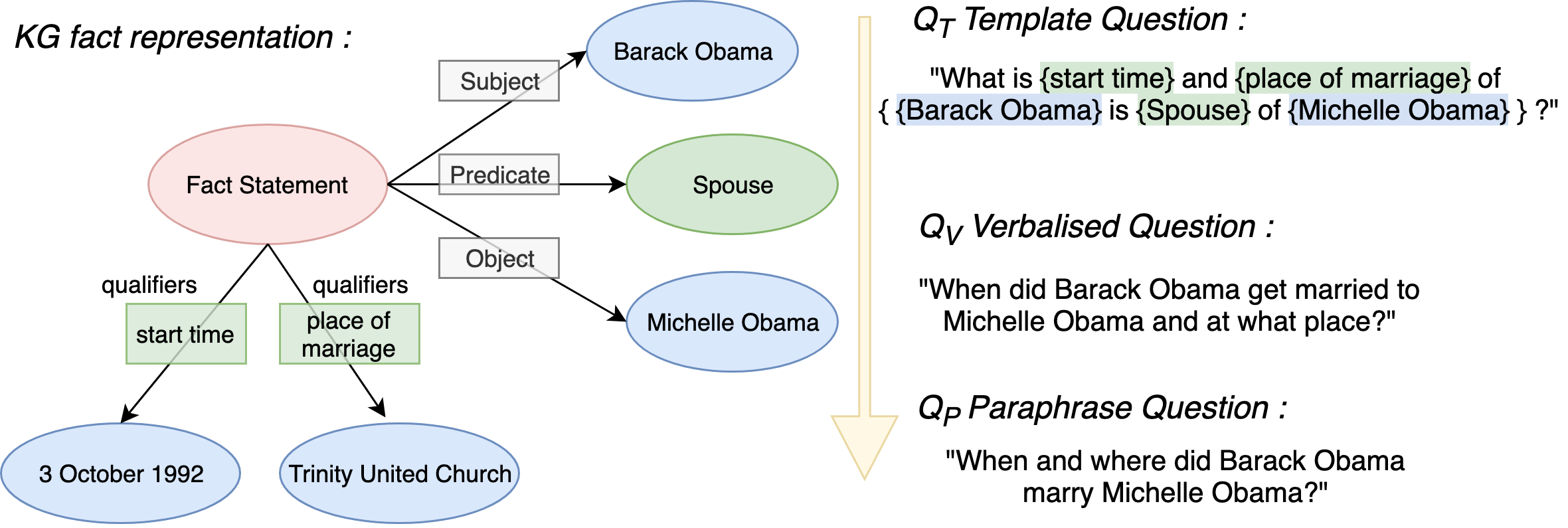
The core of the methodology is to generate SPARQL queries based on sparql templates, selected entities and suitable predicate. The SPARQL are then transformed into Template Questions QT, which acts as an intermediate stage between natural language and formal language. Then a large crowdsourcing experiment(AMT) is conducted where the QT are verbalised to natural language questions - ie verbalised questions QV and then later paraphrase them to the paraphrased questions QP