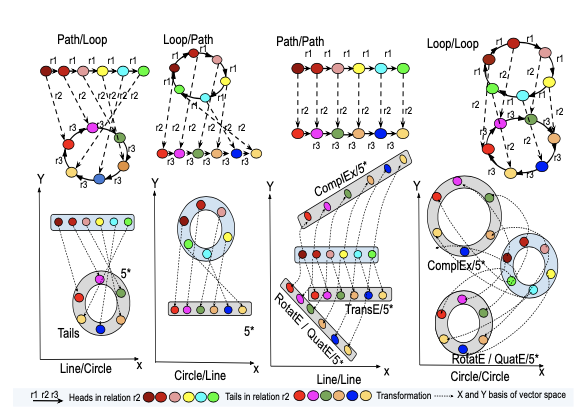
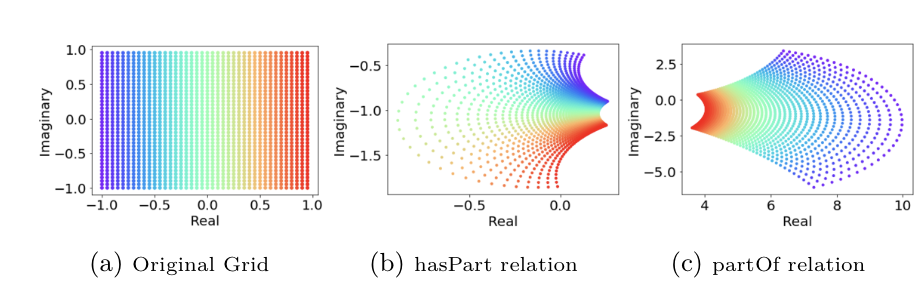
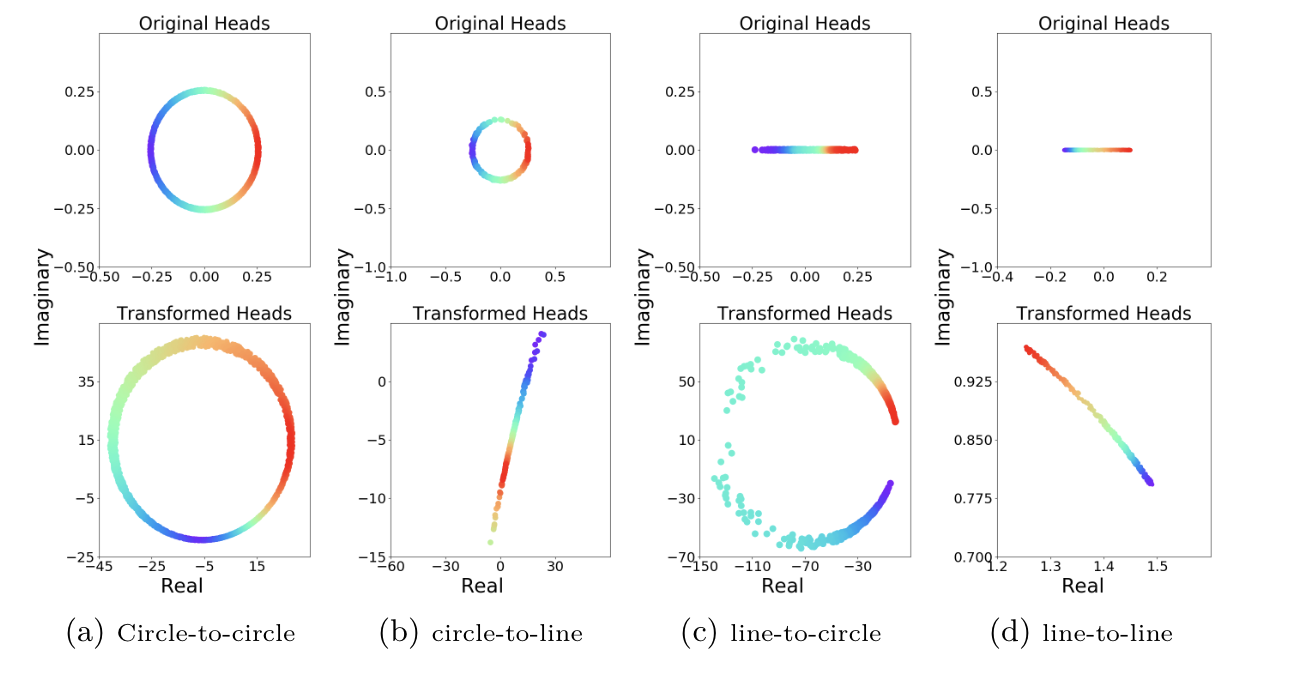
In the following, we summarize the activities of the last twelve months within the CLEOPATRA (Cross-lingual Event-centric Open Analytics Research Academy) project in which we participate.
Despite the challenges of running an international research project during a period of restricted mobility and access, the CLEOPATRA project team have enjoyed some major successes over the last twelve months. Our fourteen Early Stage Researchers (ESR) have shown remarkable ability to adapt, innovate and collaborate. They have worked together online, across different countries and time zones, to build tools and design methods for studying the digital traces of major global events. In April 2020, a hackathon and Research & Development week were quickly reorganised to be delivered virtually. Working in teams, the ESRs developed demonstrators to address such questions as how to analyse online media over time and in multiple (often under-resourced) languages. There was further opportunity to work on the demonstrators, and to develop new research ideas, at a Learning week in June 2020, held in conjunction with the University of Amsterdam Digital Methods Summer School. In January 2021, the ESRs organised a second virtual hackathon and Research & Development week, which resulted in the publication of an updated Open Event Knowledge Graph (OEKG). The OEKG is one of the key resources developed by the project, and currently contains information about more than a million events in 15 European languages. This is a unique resource which will transform our understanding of how transitional social, cultural and political events play out online. All of these activities have led to the continuation and formation of new and promising research collaborations, which we hope to see bear fruit in the coming months.
The ESRs and project beneficiaries have also been busy organising and attending conferences. In June 2020, an International Workshop on Cross-lingual Event-centric Open Analytics was held online, in association with the 17th Extended Semantic Web Conference. The award for the best paper delivered at the workshop was given to a team led by CLEOPATRA ESR, Golsa Tahmasebzadeh, working with Sherzod Hakimov, Eric Müller-Budack and Ralph Ewerth. A second international workshop will be held in April 2021, this time in association with the Web Conference. The project has been presented at numerous online conferences, in such diverse fields as the semantic web, artificial intelligence, web archive studies and spoken-language technologies. Publications arising from these events and other activities include blog posts, open datasets and no fewer than 17 conference proceedings and journal articles.
Information about all of these activities, and the various open resources that have been developed by the project team, can be found on the CLEOPATRA website, and you can follow us on Twitter @Cleopatra_ITN for the latest news and updates.